 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHVS Revisited: A Comprehensive Video Quality Assessment Framework
Paper and Code
Oct 09, 2022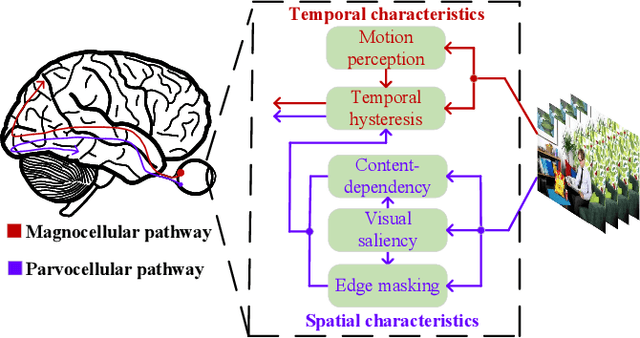



Video quality is a primary concern for video service providers. In recent years, the techniques of video quality assessment (VQA) based on deep convolutional neural networks (CNNs) have been developed rapidly. Although existing works attempt to introduce the knowledge of the human visual system (HVS) into VQA, there still exhibit limitations that prevent the full exploitation of HVS, including an incomplete model by few characteristics and insufficient connections among these characteristics. To overcome these limitations, this paper revisits HVS with five representative characteristics, and further reorganizes their connections. Based on the revisited HVS, a no-reference VQA framework called HVS-5M (NRVQA framework with five modules simulating HVS with five characteristics) is proposed. It works in a domain-fusion design paradigm with advanced network structures. On the side of the spatial domain, the visual saliency module applies SAMNet to obtain a saliency map. And then, the content-dependency and the edge masking modules respectively utilize ConvNeXt to extract the spatial features, which have been attentively weighted by the saliency map for the purpose of highlighting those regions that human beings may be interested in. On the other side of the temporal domain, to supplement the static spatial features, the motion perception module utilizes SlowFast to obtain the dynamic temporal features. Besides, the temporal hysteresis module applies TempHyst to simulate the memory mechanism of human beings, and comprehensively evaluates the quality score according to the fusion features from the spatial and temporal domains. Extensive experiments show that our HVS-5M outperforms the state-of-the-art VQA methods. Ablation studies are further conducted to verify the effectiveness of each module towards the proposed framework.