 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Factors in Model Interpretability: Industry Practices, Challenges, and Needs
Paper and Code
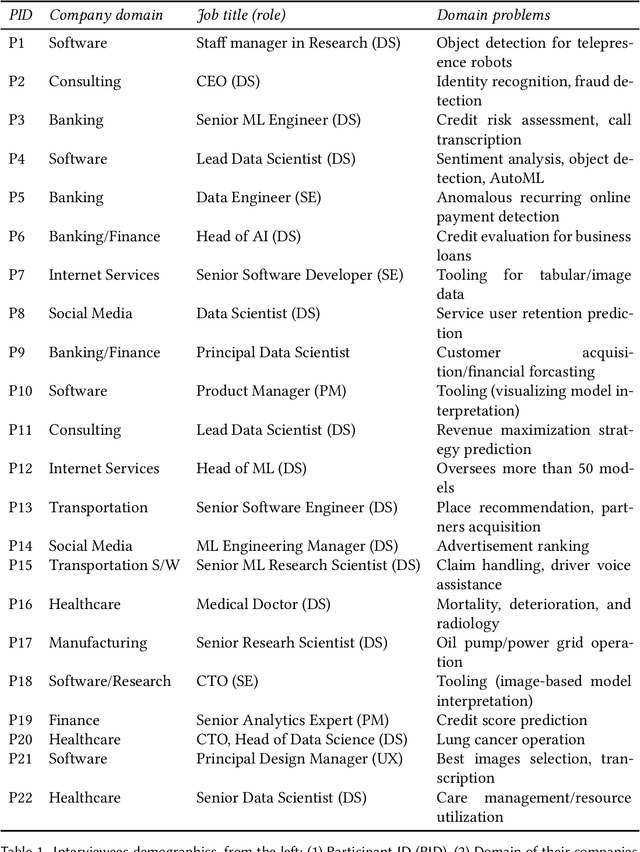
As the use of machine learning (ML) models in product development and data-driven decision-making processes became pervasive in many domains, people's focus on building a well-performing model has increasingly shifted to understanding how their model works. While scholarly interest in model interpretability has grown rapidly in research communities like HCI, ML, and beyond, little is known about how practitioners perceive and aim to provide interpretability in the context of their existing workflows. This lack of understanding of interpretability as practiced may prevent interpretability research from addressing important needs, or lead to unrealistic solutions. To bridge this gap, we conducted 22 semi-structured interviews with industry practitioners to understand how they conceive of and design for interpretability while they plan, build, and use their models. Based on a qualitative analysis of our results, we differentiate interpretability roles, processes, goals and strategies as they exist within organizations making heavy use of ML models. The characterization of interpretability work that emerges from our analysis suggests that model interpretability frequently involves cooperation and mental model comparison between people in different roles, often aimed at building trust not only between people and models but also between people within the organization. We present implications for design that discuss gaps between the interpretability challenges that practitioners face in their practice and approaches proposed in the literature, highlighting possible research directions that can better address real-world needs.