 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Activity Learning using Object Affordances from RGB-D Videos
Paper and Code
Aug 04, 2012

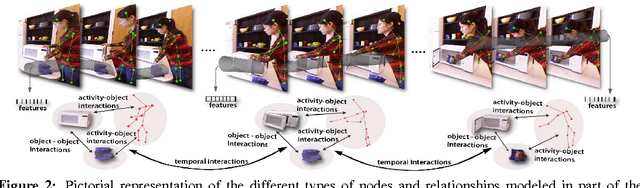
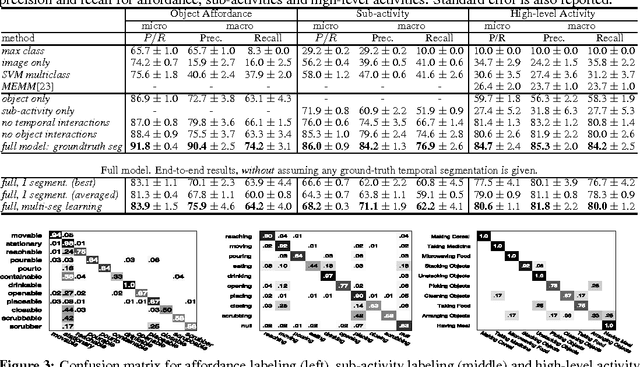
Human activities comprise several sub-activities performed in a sequence and involve interactions with various objects. This makes reasoning about the object affordances a central task for activity recognition. In this work, we consider the problem of jointly labeling the object affordances and human activities from RGB-D videos. We frame the problem as a Markov Random Field where the nodes represent objects and sub-activities, and the edges represent the relationships between object affordances, their relations with sub-activities, and their evolution over time. We formulate the learning problem using a structural SVM approach, where labeling over various alternate temporal segmentations are considered as latent variables. We tested our method on a dataset comprising 120 activity videos collected from four subjects, and obtained an end-to-end precision of 81.8% and recall of 80.0% for labeling the activities.