 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRVQA: A Visual Question Answering Benchmark for High-Resolution Aerial Images
Paper and Code
Jan 23, 2023


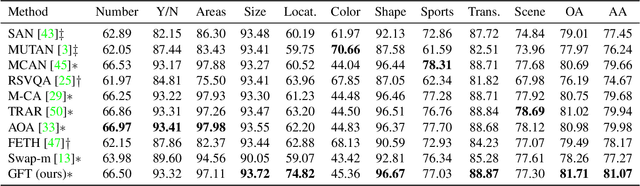
Visual question answering (VQA) is an important and challenging multimodal task in computer vision. Recently, a few efforts have been made to bring VQA task to aerial images, due to its potential real-world applications in disaster monitoring, urban planning, and digital earth product generation. However, not only the huge variation in the appearance, scale and orientation of the concepts in aerial images, but also the scarcity of the well-annotated datasets restricts the development of VQA in this domain. In this paper, we introduce a new dataset, HRVQA, which provides collected 53512 aerial images of 1024*1024 pixels and semi-automatically generated 1070240 QA pairs. To benchmark the understanding capability of VQA models for aerial images, we evaluate the relevant methods on HRVQA. Moreover, we propose a novel model, GFTransformer, with gated attention modules and a mutual fusion module. The experiments show that the proposed dataset is quite challenging, especially the specific attribute related questions. Our method achieves superior performance in comparison to the previous state-of-the-art approaches. The dataset and the source code will be released at https://hrvqa.nl/.