 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Train-Test Leakage Affects Zero-shot Retrieval
Paper and Code

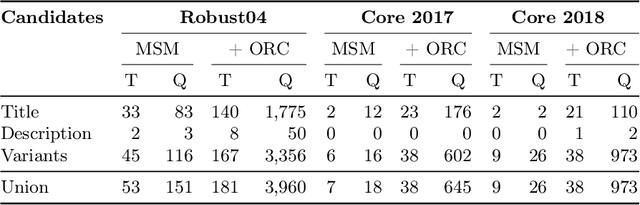
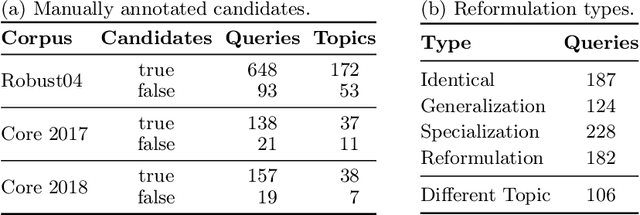
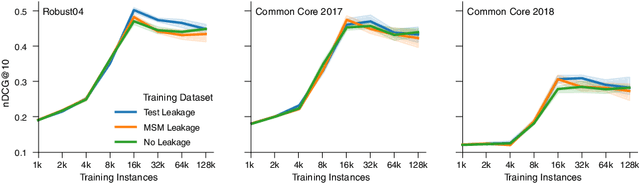
Neural retrieval models are often trained on (subsets of) the millions of queries of the MS MARCO / ORCAS datasets and then tested on the 250 Robust04 queries or other TREC benchmarks with often only 50 queries. In such setups, many of the few test queries can be very similar to queries from the huge training data -- in fact, 69% of the Robust04 queries have near-duplicates in MS MARCO / ORCAS. We investigate the impact of this unintended train-test leakage by training neural retrieval models on combinations of a fixed number of MS MARCO / ORCAS queries that are highly similar to the actual test queries and an increasing number of other queries. We find that leakage can improve effectiveness and even change the ranking of systems. However, these effects diminish as the amount of leakage among all training instances decreases and thus becomes more realistic.