 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Train Vision Transformer on Small-scale Datasets?
Paper and Code


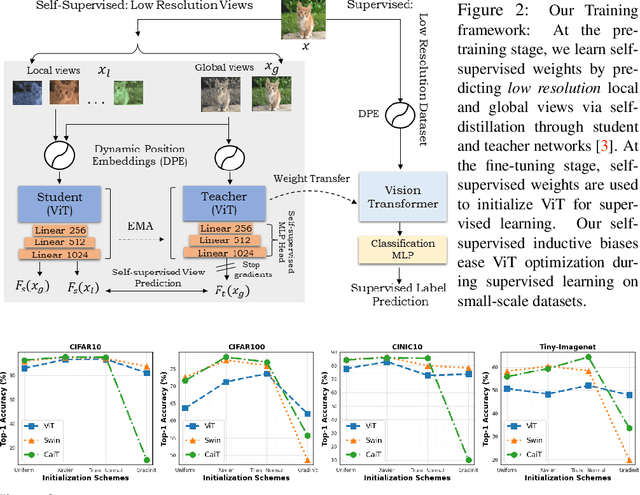

Vision Transformer (ViT), a radically different architecture than convolutional neural networks offers multiple advantages including design simplicity, robustness and state-of-the-art performance on many vision tasks. However, in contrast to convolutional neural networks, Vision Transformer lacks inherent inductive biases. Therefore, successful training of such models is mainly attributed to pre-training on large-scale datasets such as ImageNet with 1.2M or JFT with 300M images. This hinders the direct adaption of Vision Transformer for small-scale datasets. In this work, we show that self-supervised inductive biases can be learned directly from small-scale datasets and serve as an effective weight initialization scheme for fine-tuning. This allows to train these models without large-scale pre-training, changes to model architecture or loss functions. We present thorough experiments to successfully train monolithic and non-monolithic Vision Transformers on five small datasets including CIFAR10/100, CINIC10, SVHN, Tiny-ImageNet and two fine-grained datasets: Aircraft and Cars. Our approach consistently improves the performance of Vision Transformers while retaining their properties such as attention to salient regions and higher robustness. Our codes and pre-trained models are available at: https://github.com/hananshafi/vits-for-small-scale-datasets.