 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to talk so your robot will learn: Instructions, descriptions, and pragmatics
Paper and Code
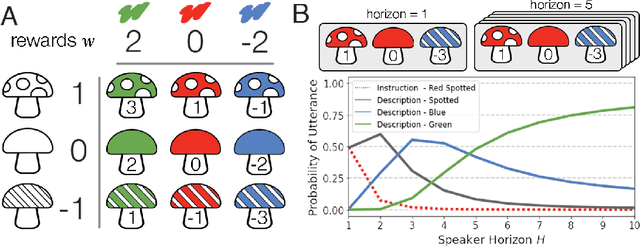
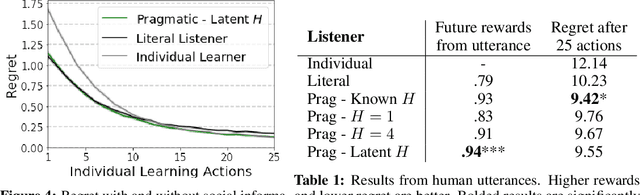
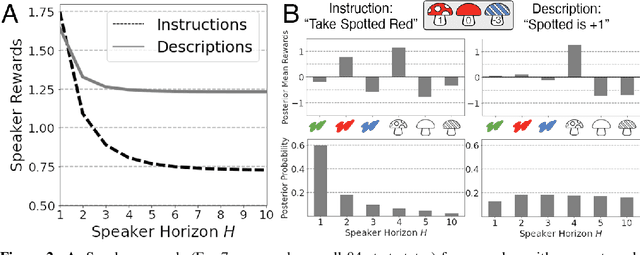
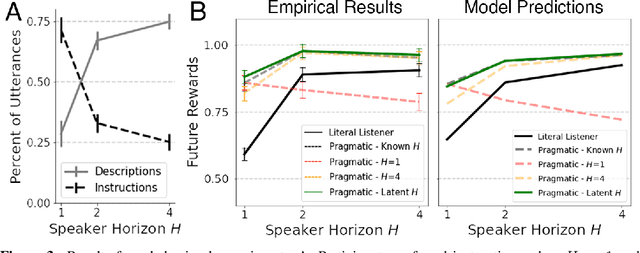
From the earliest years of our lives, humans use language to express our beliefs and desires. Being able to talk to artificial agents about our preferences would thus fulfill a central goal of value alignment. Yet today, we lack computational models explaining such flexible and abstract language use. To address this challenge, we consider social learning in a linear bandit setting and ask how a human might communicate preferences over behaviors (i.e. the reward function). We study two distinct types of language: instructions, which provide information about the desired policy, and descriptions, which provide information about the reward function. To explain how humans use these forms of language, we suggest they reason about both known present and unknown future states: instructions optimize for the present, while descriptions generalize to the future. We formalize this choice by extending reward design to consider a distribution over states. We then define a pragmatic listener agent that infers the speaker's reward function by reasoning about how the speaker expresses themselves. We validate our models with a behavioral experiment, demonstrating that (1) our speaker model predicts spontaneous human behavior, and (2) our pragmatic listener is able to recover their reward functions. Finally, we show that in traditional reinforcement learning settings, pragmatic social learning can integrate with and accelerate individual learning. Our findings suggest that social learning from a wider range of language -- in particular, expanding the field's present focus on instructions to include learning from descriptions -- is a promising approach for value alignment and reinforcement learning more broadly.