 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Ask Better Questions? A Large-Scale Multi-Domain Dataset for Rewriting Ill-Formed Questions
Paper and Code

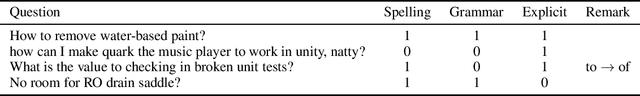


We present a large-scale dataset for the task of rewriting an ill-formed natural language question to a well-formed one. Our multi-domain question rewriting MQR dataset is constructed from human contributed Stack Exchange question edit histories. The dataset contains 427,719 question pairs which come from 303 domains. We provide human annotations for a subset of the dataset as a quality estimate. When moving from ill-formed to well-formed questions, the question quality improves by an average of 45 points across three aspects. We train sequence-to-sequence neural models on the constructed dataset and obtain an improvement of 13.2% in BLEU-4 over baseline methods built from other data resources. We release the MQR dataset to encourage research on the problem of question rewriting.