 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow (Non-)Optimal is the Lexicon?
Paper and Code
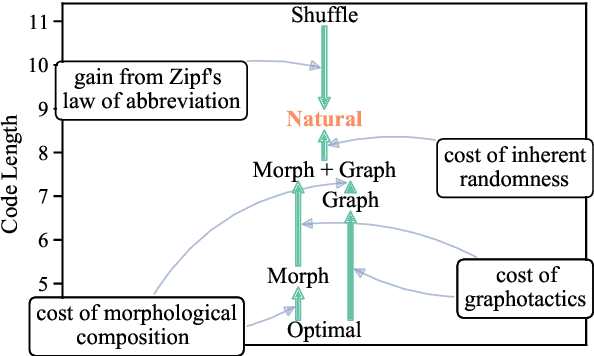
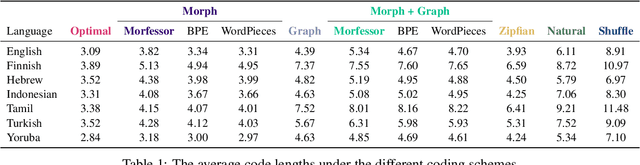
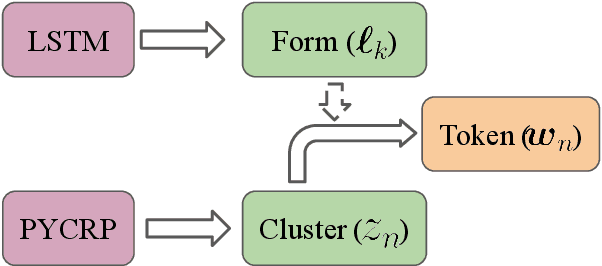
The mapping of lexical meanings to wordforms is a major feature of natural languages. While usage pressures might assign short words to frequent meanings (Zipf's law of abbreviation), the need for a productive and open-ended vocabulary, local constraints on sequences of symbols, and various other factors all shape the lexicons of the world's languages. Despite their importance in shaping lexical structure, the relative contributions of these factors have not been fully quantified. Taking a coding-theoretic view of the lexicon and making use of a novel generative statistical model, we define upper bounds for the compressibility of the lexicon under various constraints. Examining corpora from 7 typologically diverse languages, we use those upper bounds to quantify the lexicon's optimality and to explore the relative costs of major constraints on natural codes. We find that (compositional) morphology and graphotactics can sufficiently account for most of the complexity of natural codes -- as measured by code length.