 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow much do language models copy from their training data? Evaluating linguistic novelty in text generation using RAVEN
Paper and Code
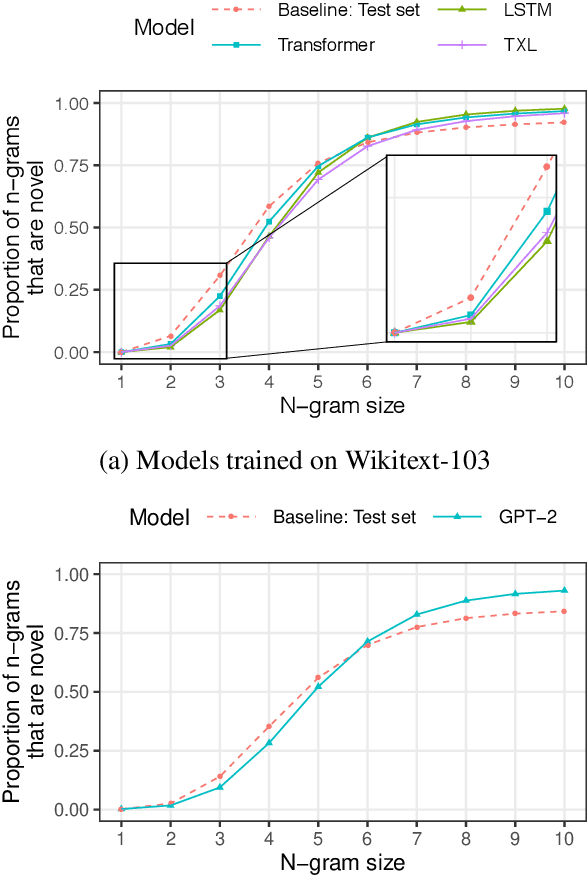
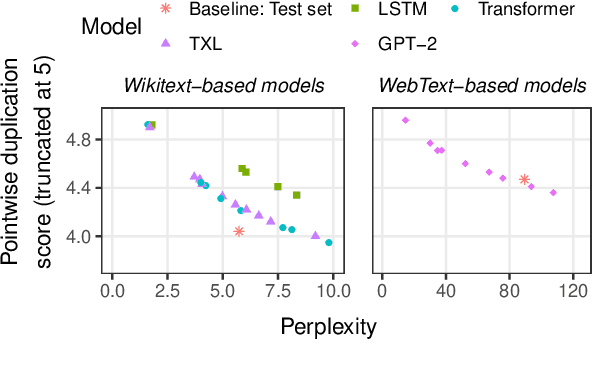
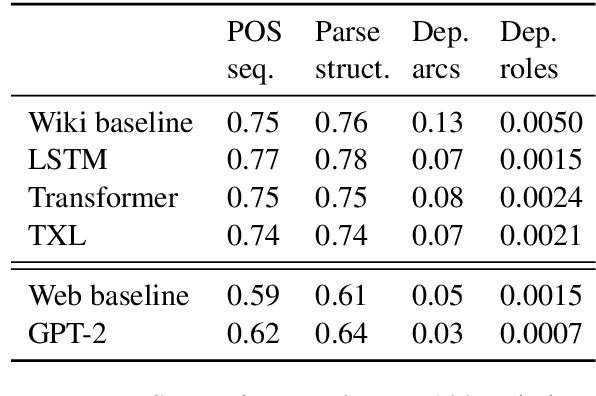
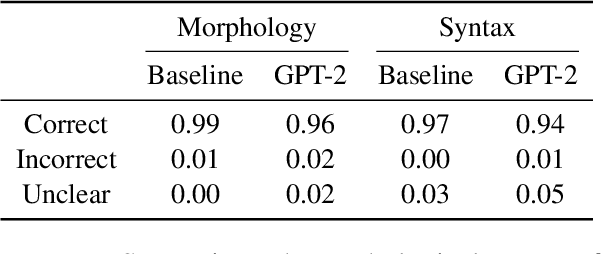
Current language models can generate high-quality text. Are they simply copying text they have seen before, or have they learned generalizable linguistic abstractions? To tease apart these possibilities, we introduce RAVEN, a suite of analyses for assessing the novelty of generated text, focusing on sequential structure (n-grams) and syntactic structure. We apply these analyses to four neural language models (an LSTM, a Transformer, Transformer-XL, and GPT-2). For local structure - e.g., individual dependencies - model-generated text is substantially less novel than our baseline of human-generated text from each model's test set. For larger-scale structure - e.g., overall sentence structure - model-generated text is as novel or even more novel than the human-generated baseline, but models still sometimes copy substantially, in some cases duplicating passages over 1,000 words long from the training set. We also perform extensive manual analysis showing that GPT-2's novel text is usually well-formed morphologically and syntactically but has reasonably frequent semantic issues (e.g., being self-contradictory).