 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do neural networks see depth in single images?
Paper and Code
May 16, 2019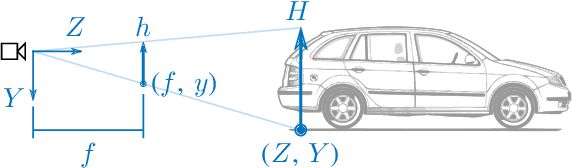
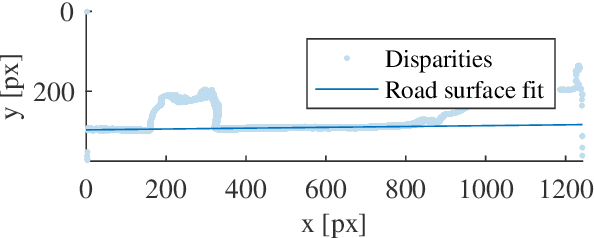
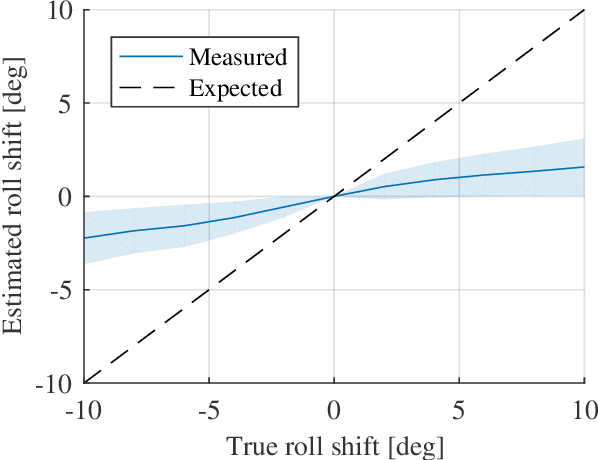
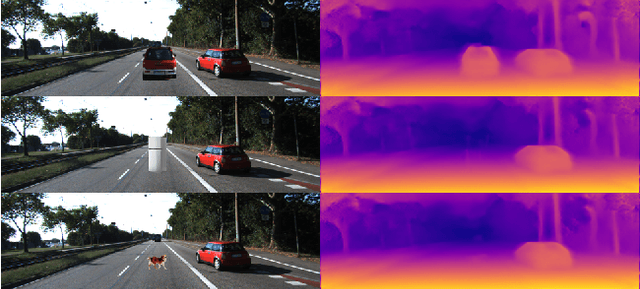
Deep neural networks have lead to a breakthrough in depth estimation from single images. Recent work often focuses on the accuracy of the depth map, where an evaluation on a publicly available test set such as the KITTI vision benchmark is often the main result of the article. While such an evaluation shows how well neural networks can estimate depth, it does not show how they do this. To the best of our knowledge, no work currently exists that analyzes what these networks have learned. In this work we take the MonoDepth network by Godard et al. and investigate what visual cues it exploits for depth estimation. We find that the network ignores the apparent size of known obstacles in favor of their vertical position in the image. Using the vertical position requires the camera pose to be known; however we find that MonoDepth only partially corrects for changes in camera pitch and roll and that these influence the estimated depth towards obstacles. We further show that MonoDepth's use of the vertical image position allows it to estimate the distance towards arbitrary obstacles, even those not appearing in the training set, but that it requires a strong edge at the ground contact point of the object to do so. In future work we will investigate whether these observations also apply to other neural networks for monocular depth estimation.