 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiPPO-Prophecy: State-Space Models can Provably Learn Dynamical Systems in Context
Paper and Code
Jul 12, 2024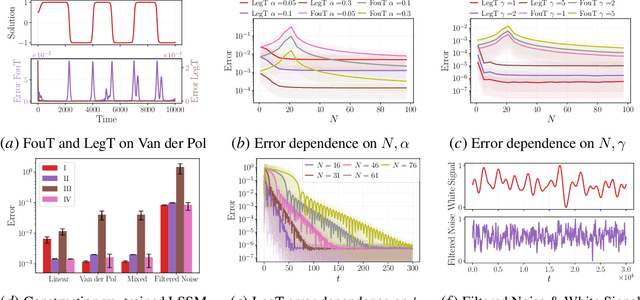

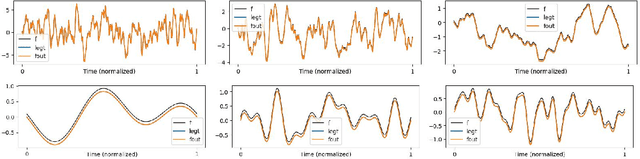

This work explores the in-context learning capabilities of State Space Models (SSMs) and presents, to the best of our knowledge, the first theoretical explanation of a possible underlying mechanism. We introduce a novel weight construction for SSMs, enabling them to predict the next state of any dynamical system after observing previous states without parameter fine-tuning. This is accomplished by extending the HiPPO framework to demonstrate that continuous SSMs can approximate the derivative of any input signal. Specifically, we find an explicit weight construction for continuous SSMs and provide an asymptotic error bound on the derivative approximation. The discretization of this continuous SSM subsequently yields a discrete SSM that predicts the next state. Finally, we demonstrate the effectiveness of our parameterization empirically. This work should be an initial step toward understanding how sequence models based on SSMs learn in context.