 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Resolution Face Age Editing
Paper and Code


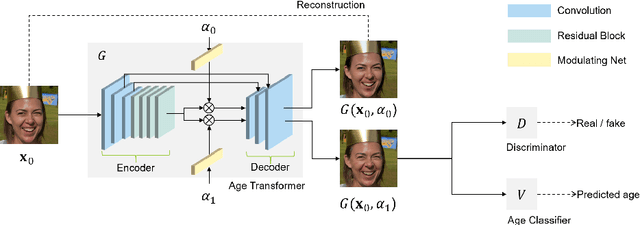
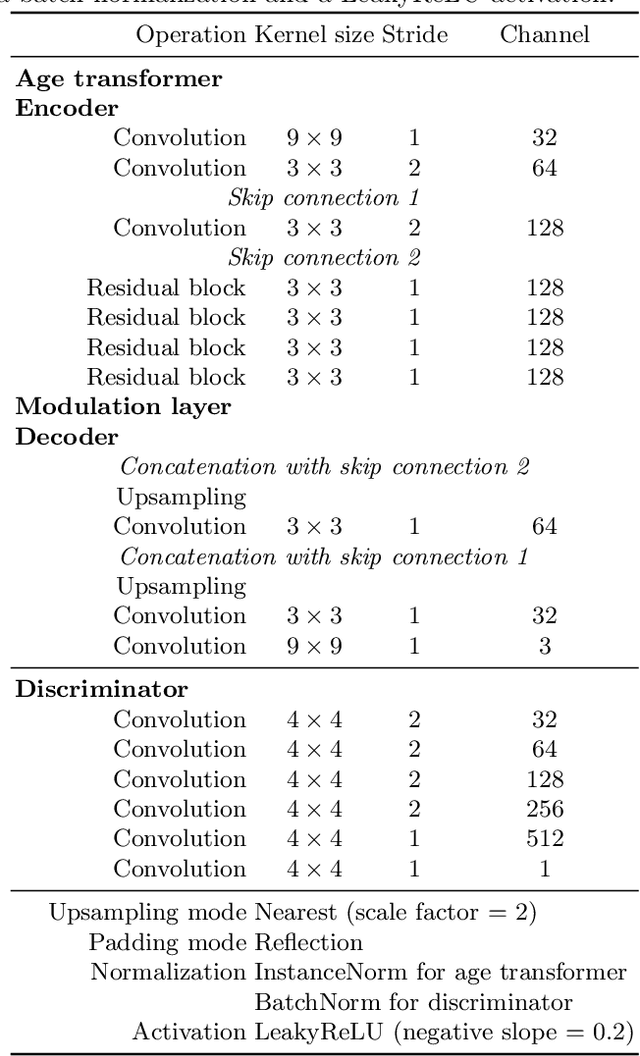
Face age editing has become a crucial task in film post-production, and is also becoming popular for general purpose photography. Recently, adversarial training has produced some of the most visually impressive results for image manipulation, including the face aging/de-aging task. In spite of considerable progress, current methods often present visual artifacts and can only deal with low-resolution images. In order to achieve aging/de-aging with the high quality and robustness necessary for wider use, these problems need to be addressed. This is the goal of the present work. We present an encoder-decoder architecture for face age editing. The core idea of our network is to create both a latent space containing the face identity, and a feature modulation layer corresponding to the age of the individual. We then combine these two elements to produce an output image of the person with a desired target age. Our architecture is greatly simplified with respect to other approaches, and allows for continuous age editing on high resolution images in a single unified model.