 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional dynamics of generalization error in neural networks
Paper and Code
Oct 10, 2017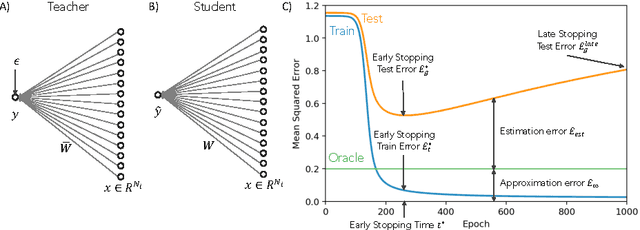
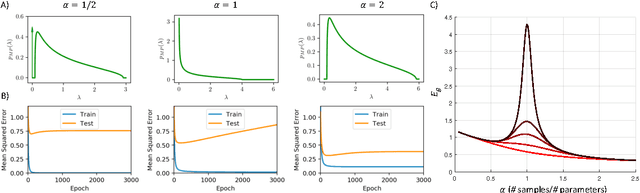
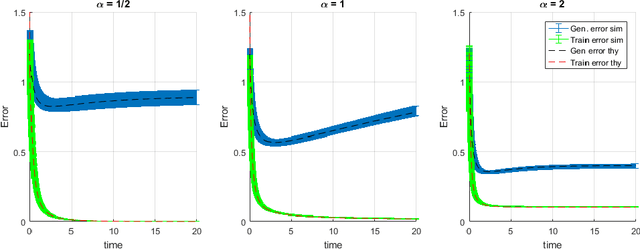
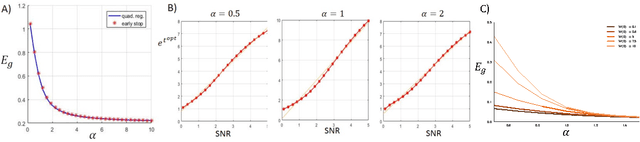
We perform an average case analysis of the generalization dynamics of large neural networks trained using gradient descent. We study the practically-relevant "high-dimensional" regime where the number of free parameters in the network is on the order of or even larger than the number of examples in the dataset. Using random matrix theory and exact solutions in linear models, we derive the generalization error and training error dynamics of learning and analyze how they depend on the dimensionality of data and signal to noise ratio of the learning problem. We find that the dynamics of gradient descent learning naturally protect against overtraining and overfitting in large networks. Overtraining is worst at intermediate network sizes, when the effective number of free parameters equals the number of samples, and thus can be reduced by making a network smaller or larger. Additionally, in the high-dimensional regime, low generalization error requires starting with small initial weights. We then turn to non-linear neural networks, and show that making networks very large does not harm their generalization performance. On the contrary, it can in fact reduce overtraining, even without early stopping or regularization of any sort. We identify two novel phenomena underlying this behavior in overcomplete models: first, there is a frozen subspace of the weights in which no learning occurs under gradient descent; and second, the statistical properties of the high-dimensional regime yield better-conditioned input correlations which protect against overtraining. We demonstrate that naive application of worst-case theories such as Rademacher complexity are inaccurate in predicting the generalization performance of deep neural networks, and derive an alternative bound which incorporates the frozen subspace and conditioning effects and qualitatively matches the behavior observed in simulation.