 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Dimensional Classification via Empirical Risk Minimization: Improvements and Optimality
Paper and Code
May 31, 2019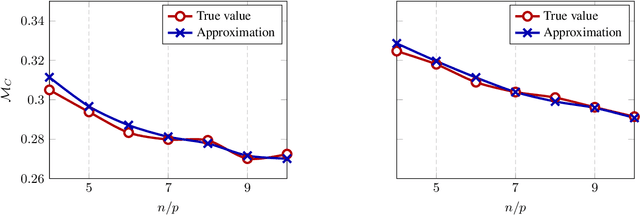
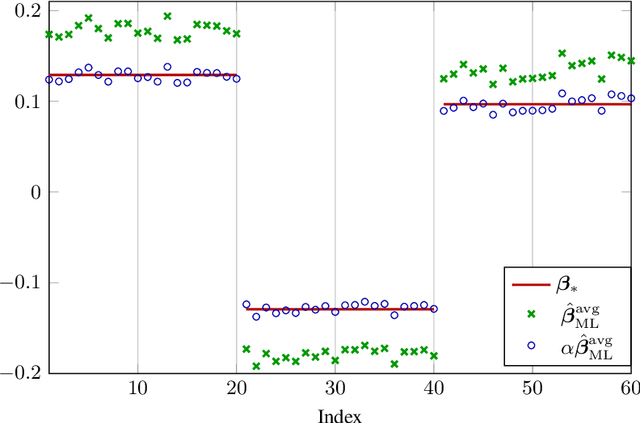
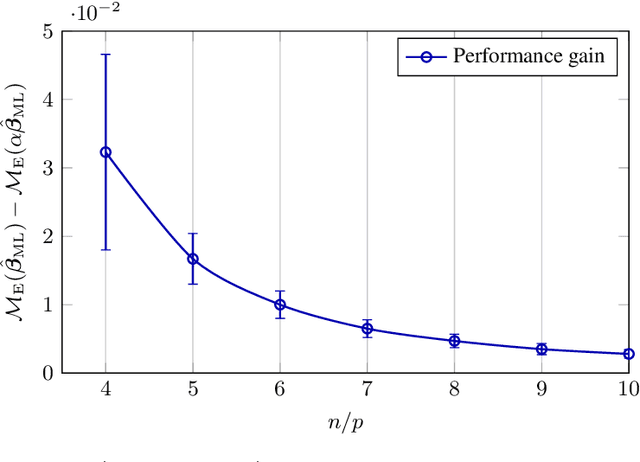
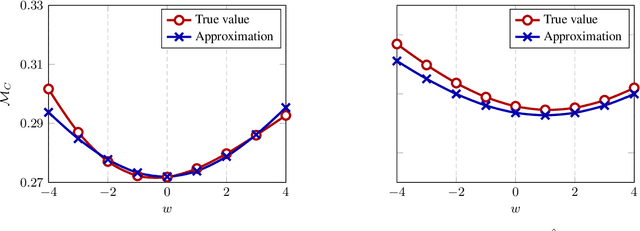
In this article, we investigate a family of classification algorithms defined by the principle of empirical risk minimization, in the high dimensional regime where the feature dimension $p$ and data number $n$ are both large and comparable. Based on recent advances in high dimensional statistics and random matrix theory, we provide under mixture data model a unified stochastic characterization of classifiers learned with different loss functions. Our results are instrumental to an in-depth understanding as well as practical improvements on this fundamental classification approach. As the main outcome, we demonstrate the existence of a universally optimal loss function which yields the best high dimensional performance at any given $n/p$ ratio.