 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Transformer Networks for Longitudinal Clinical Document Classification
Paper and Code
Apr 17, 2021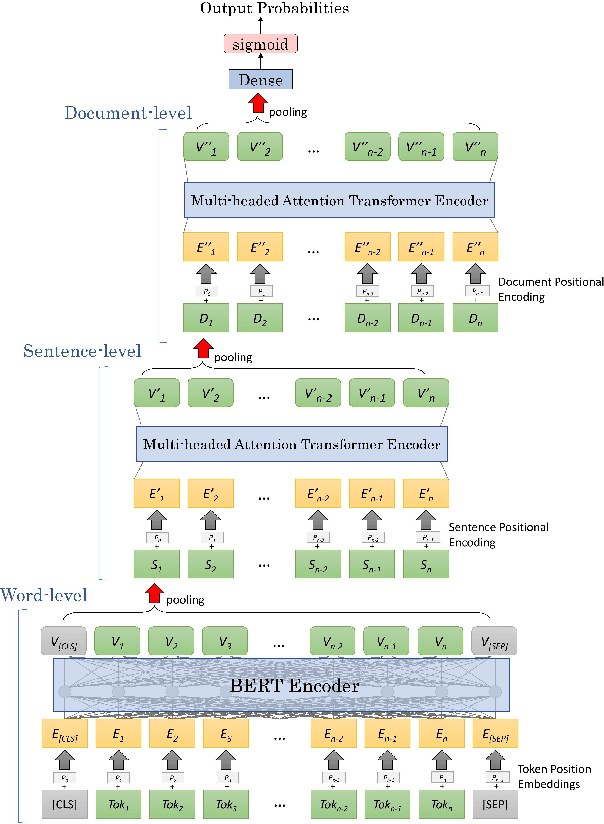

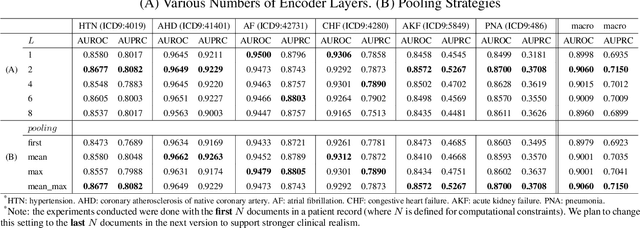
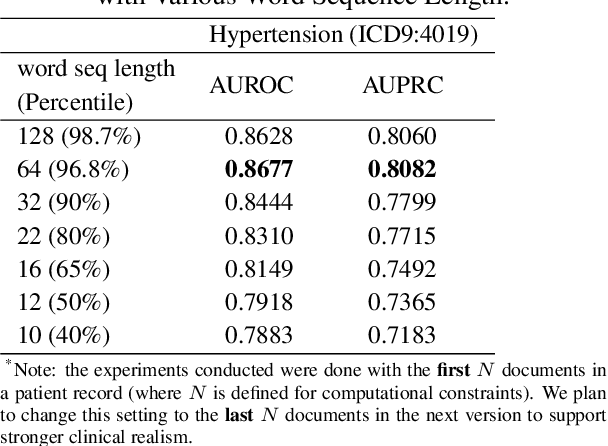
We present the Hierarchical Transformer Networks for modeling long-term dependencies across clinical notes for the purpose of patient-level prediction. The network is equipped with three levels of Transformer-based encoders to learn progressively from words to sentences, sentences to notes, and finally notes to patients. The first level from word to sentence directly applies a pre-trained BERT model, and the second and third levels both implement a stack of 2-layer encoders before the final patient representation is fed into the classification layer for clinical predictions. Compared to traditional BERT models, our model increases the maximum input length from 512 words to much longer sequences that are appropriate for long sequences of clinical notes. We empirically examine and experiment with different parameters to identify an optimal trade-off given computational resource limits. Our experimental results on the MIMIC-III dataset for different prediction tasks demonstrate that our proposed hierarchical model outperforms previous state-of-the-art hierarchical neural networks.