 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Reinforcement Learning for Concurrent Discovery of Compound and Composable Policies
Paper and Code
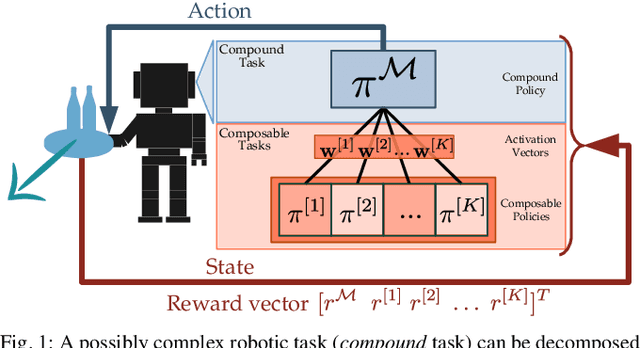

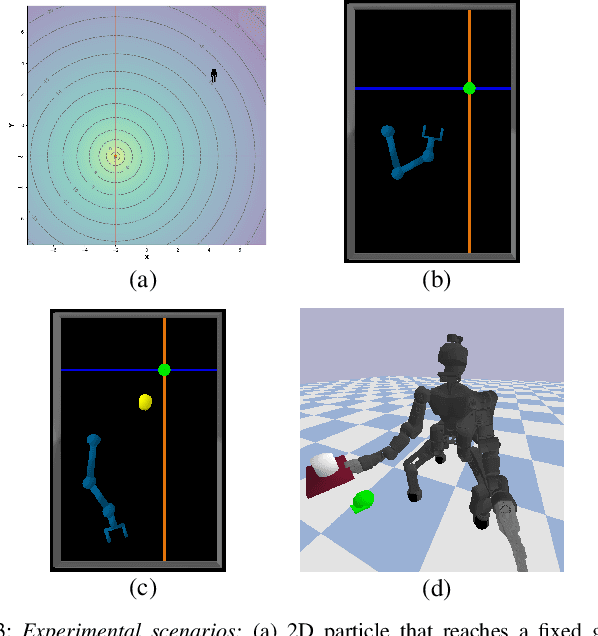

A common strategy to deal with the expensive reinforcement learning (RL) of complex tasks is to decompose them into a collection of subtasks that are usually simpler to learn as well as reusable for new problems. However, when a robot learns the policies for these subtasks, common approaches treat every policy learning process separately. Therefore, all these individual (composable) policies need to be learned before tackling the learning process of the complex task through policies composition. Such composition of individual policies is usually performed sequentially, which is not suitable for tasks that require to perform the subtasks concurrently. In this paper, we propose to combine a set of composable Gaussian policies corresponding to these subtasks using a set of activation vectors, resulting in a complex Gaussian policy that is a function of the means and covariances matrices of the composable policies. Moreover, we propose an algorithm for learning both compound and composable policies within the same learning process by exploiting the off-policy data generated from the compound policy. The algorithm is built on a maximum entropy RL approach to favor exploration during the learning process. The results of the experiments show that the experience collected with the compound policy permits not only to solve the complex task but also to obtain useful composable policies that successfully perform in their respective tasks. Supplementary videos and code are available at https://sites.google.com/view/hrl-concurrent-discovery .