 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Neural Data Synthesis for Semantic Parsing
Paper and Code
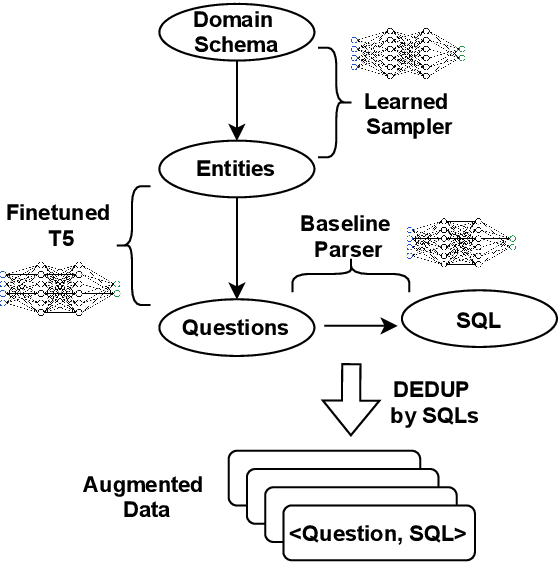

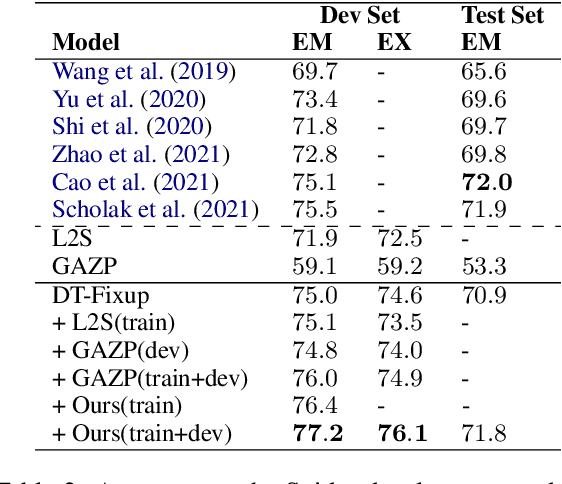
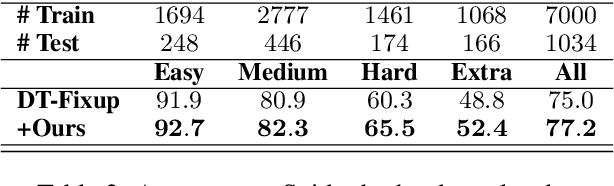
Semantic parsing datasets are expensive to collect. Moreover, even the questions pertinent to a given domain, which are the input of a semantic parsing system, might not be readily available, especially in cross-domain semantic parsing. This makes data augmentation even more challenging. Existing methods to synthesize new data use hand-crafted or induced rules, requiring substantial engineering effort and linguistic expertise to achieve good coverage and precision, which limits the scalability. In this work, we propose a purely neural approach of data augmentation for semantic parsing that completely removes the need for grammar engineering while achieving higher semantic parsing accuracy. Furthermore, our method can synthesize in the zero-shot setting, where only a new domain schema is available without any input-output examples of the new domain. On the Spider cross-domain text-to-SQL semantic parsing benchmark, we achieve the state-of-the-art performance on the development set (77.2% accuracy) using our zero-shot augmentation.