 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Graph Neural Networks for Software Effort Estimation
Paper and Code
Jun 30, 2022
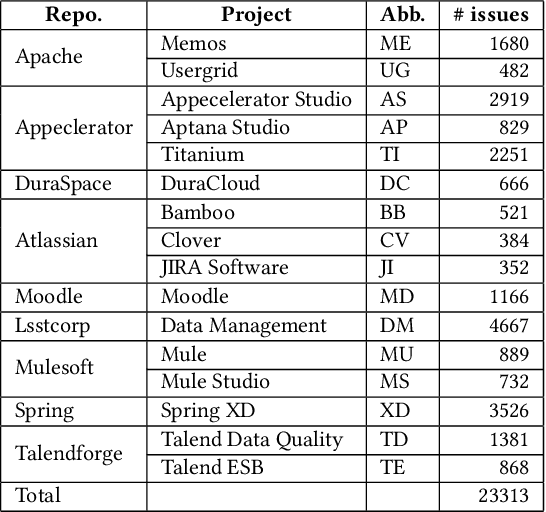

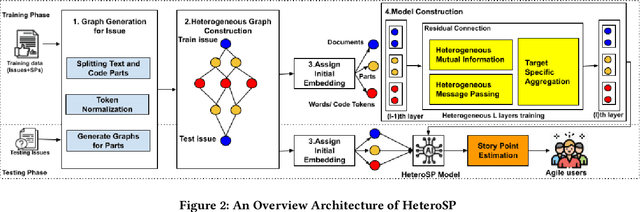
Software effort can be measured by story point [35]. Current approaches for automatically estimating story points focus on applying pre-trained embedding models and deep learning for text regression to solve this problem which required expensive embedding models. We propose HeteroSP, a tool for estimating story points from textual input of Agile software project issues. We select GPT2SP [12] and Deep-SE [8] as the baselines for comparison. First, from the analysis of the story point dataset [8], we conclude that software issues are actually a mixture of natural language sentences with quoted code snippets and have problems related to large-size vocabulary. Second, we provide a module to normalize the input text including words and code tokens of the software issues. Third, we design an algorithm to convert an input software issue to a graph with different types of nodes and edges. Fourth, we construct a heterogeneous graph neural networks model with the support of fastText [6] for constructing initial node embedding to learn and predict the story points of new issues. We did the comparison over three scenarios of estimation, including within project, cross-project within the repository, and cross-project cross repository with our baseline approaches. We achieve the average Mean Absolute Error (MAE) as 2.38, 2.61, and 2.63 for three scenarios. We outperform GPT2SP in 2/3 of the scenarios while outperforming Deep-SE in the most challenging scenario with significantly less amount of running time. We also compare our approaches with different homogeneous graph neural network models and the results show that the heterogeneous graph neural networks model outperforms the homogeneous models in story point estimation. For time performance, we achieve about 570 seconds as the time performance in both three processes: node embedding initialization, model construction, and story point estimation.