 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHashing Learning with Hyper-Class Representation
Paper and Code
Jun 06, 2022

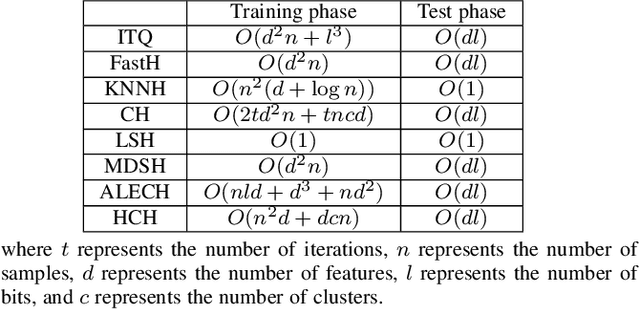
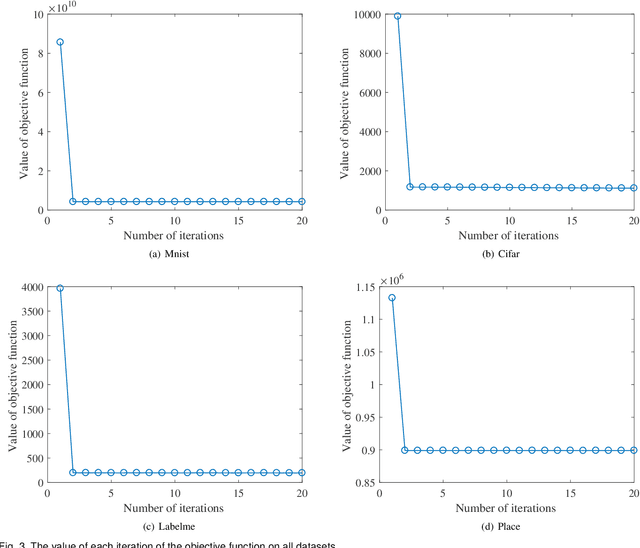
Existing unsupervised hash learning is a kind of attribute-centered calculation. It may not accurately preserve the similarity between data. This leads to low down the performance of hash function learning. In this paper, a hash algorithm is proposed with a hyper-class representation. It is a two-steps approach. The first step finds potential decision features and establish hyper-class. The second step constructs hash learning based on the hyper-class information in the first step, so that the hash codes of the data within the hyper-class are as similar as possible, as well as the hash codes of the data between the hyper-classes are as different as possible. To evaluate the efficiency, a series of experiments are conducted on four public datasets. The experimental results show that the proposed hash algorithm is more efficient than the compared algorithms, in terms of mean average precision (MAP), average precision (AP) and Hamming radius 2 (HAM2)