Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Multilingual Resources to Question Answering in Arabic
Paper and Code
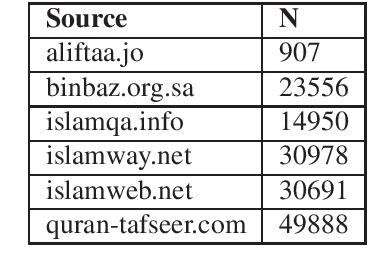
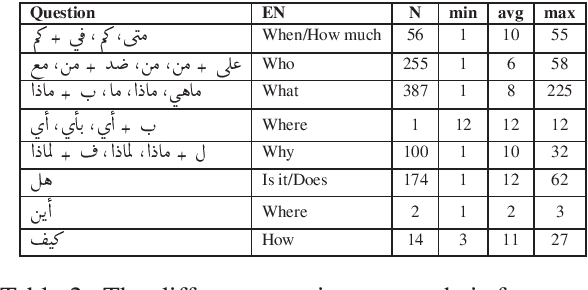


The goal of the paper is to predict answers to questions given a passage of Qur'an. The answers are always found in the passage, so the task of the model is to predict where an answer starts and where it ends. As the initial data set is rather small for training, we make use of multilingual BERT so that we can augment the training data by using data available for languages other than Arabic. Furthermore, we crawl a large Arabic corpus that is domain specific to religious discourse. Our approach consists of two steps, first we train a BERT model to predict a set of possible answers in a passage. Finally, we use another BERT based model to rank the candidate answers produced by the first BERT model.
View paper on