 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-efficient on-line learning through pipelined truncated-error backpropagation in binary-state networks
Paper and Code
Aug 16, 2017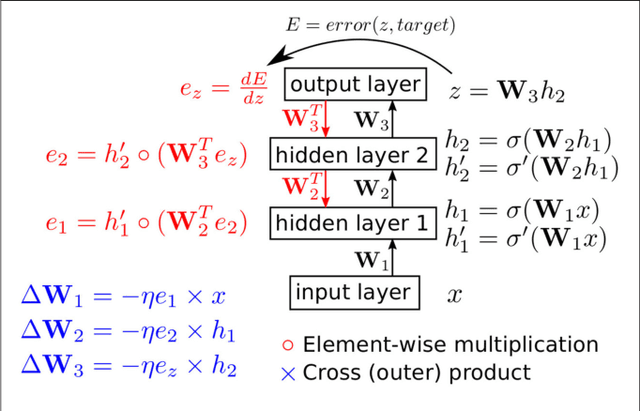
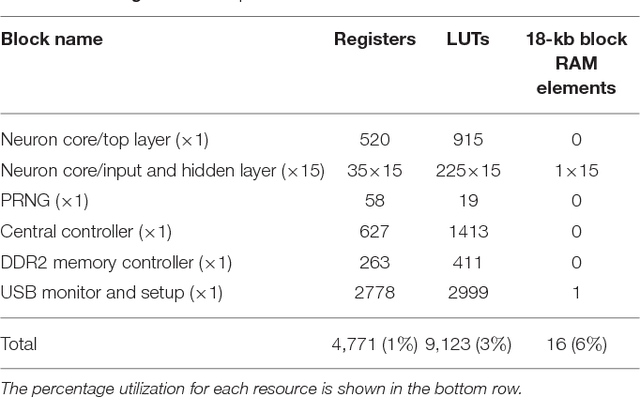
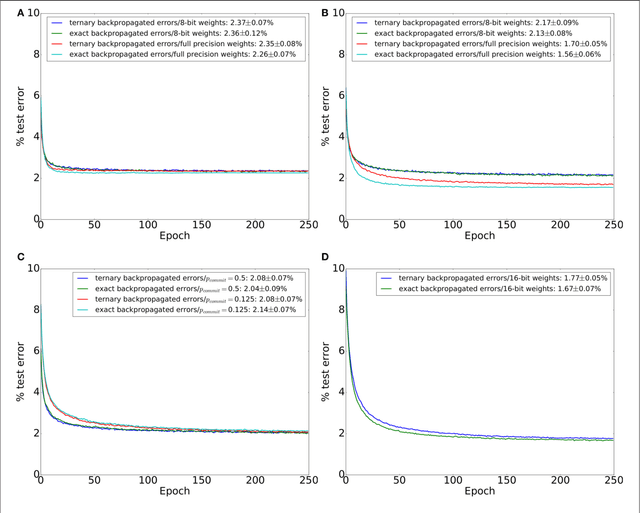

Artificial neural networks (ANNs) trained using backpropagation are powerful learning architectures that have achieved state-of-the-art performance in various benchmarks. Significant effort has been devoted to developing custom silicon devices to accelerate inference in ANNs. Accelerating the training phase, however, has attracted relatively little attention. In this paper, we describe a hardware-efficient on-line learning technique for feedforward multi-layer ANNs that is based on pipelined backpropagation. Learning is performed in parallel with inference in the forward pass, removing the need for an explicit backward pass and requiring no extra weight lookup. By using binary state variables in the feedforward network and ternary errors in truncated-error backpropagation, the need for any multiplications in the forward and backward passes is removed, and memory requirements for the pipelining are drastically reduced. Further reduction in addition operations owing to the sparsity in the forward neural and backpropagating error signal paths contributes to highly efficient hardware implementation. For proof-of-concept validation, we demonstrate on-line learning of MNIST handwritten digit classification on a Spartan 6 FPGA interfacing with an external 1Gb DDR2 DRAM, that shows small degradation in test error performance compared to an equivalently sized binary ANN trained off-line using standard back-propagation and exact errors. Our results highlight an attractive synergy between pipelined backpropagation and binary-state networks in substantially reducing computation and memory requirements, making pipelined on-line learning practical in deep networks.