 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardness of Samples Need to be Quantified for a Reliable Evaluation System: Exploring Potential Opportunities with a New Task
Paper and Code
Oct 14, 2022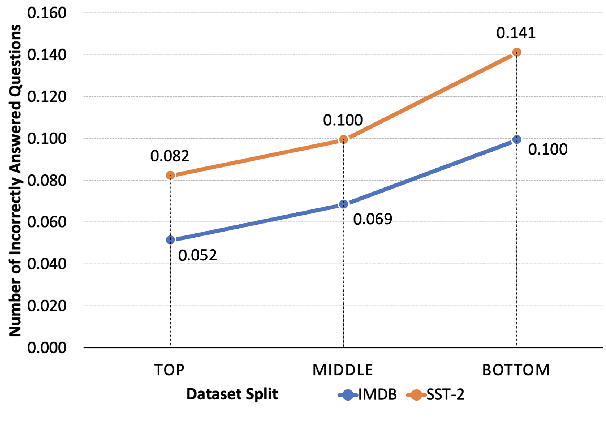
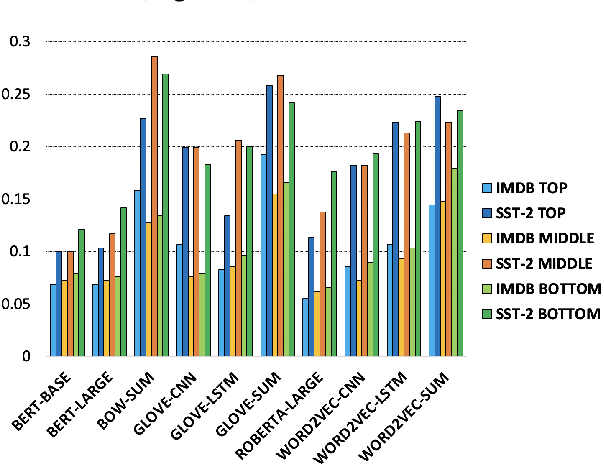
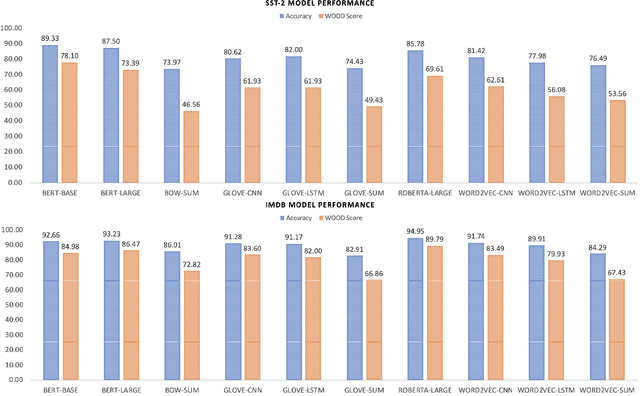
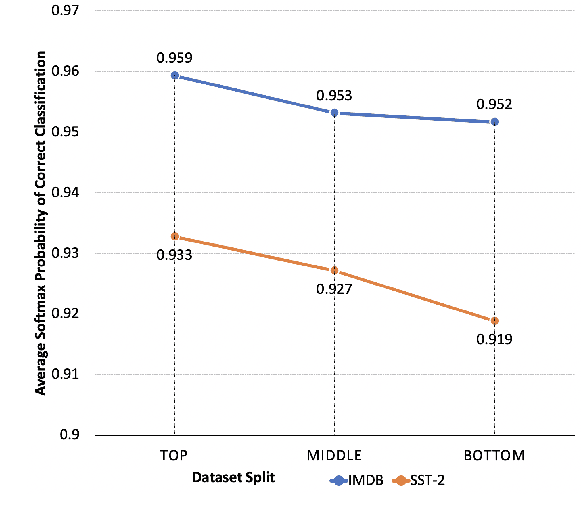
Evaluation of models on benchmarks is unreliable without knowing the degree of sample hardness; this subsequently overestimates the capability of AI systems and limits their adoption in real world applications. We propose a Data Scoring task that requires assignment of each unannotated sample in a benchmark a score between 0 to 1, where 0 signifies easy and 1 signifies hard. Use of unannotated samples in our task design is inspired from humans who can determine a question difficulty without knowing its correct answer. This also rules out the use of methods involving model based supervision (since they require sample annotations to get trained), eliminating potential biases associated with models in deciding sample difficulty. We propose a method based on Semantic Textual Similarity (STS) for this task; we validate our method by showing that existing models are more accurate with respect to the easier sample-chunks than with respect to the harder sample-chunks. Finally we demonstrate five novel applications.