 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Incomplete Heterogeneous Data using VAEs
Paper and Code



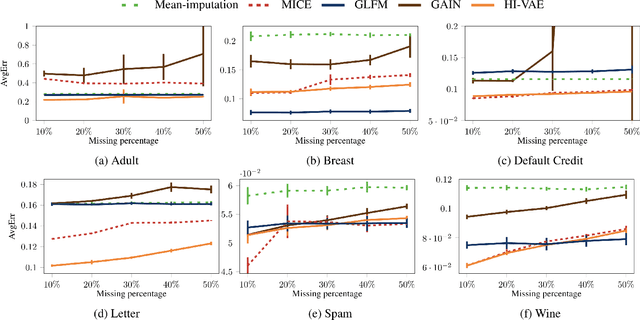
Variational autoencoders (VAEs), as well as other generative models, have been shown to be efficient and accurate to capture the latent structure of vast amounts of complex high-dimensional data. However, existing VAEs can still not directly handle data that are heterogenous (mixed continuous and discrete) or incomplete (with missing data at random), which is indeed common in real-world applications. In this paper, we propose a general framework to design VAEs, suitable for fitting incomplete heterogenous data. The proposed HI-VAE includes likelihood models for real-valued, positive real valued, interval, categorical, ordinal and count data, and allows to estimate (and potentially impute) missing data accurately. Furthermore, HI-VAE presents competitive predictive performance in supervised tasks, outperforming super- vised models when trained on incomplete data