 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-VECTORS: Utterance-level Speaker Embedding Using A Hierarchical Attention Model
Paper and Code
Oct 19, 2019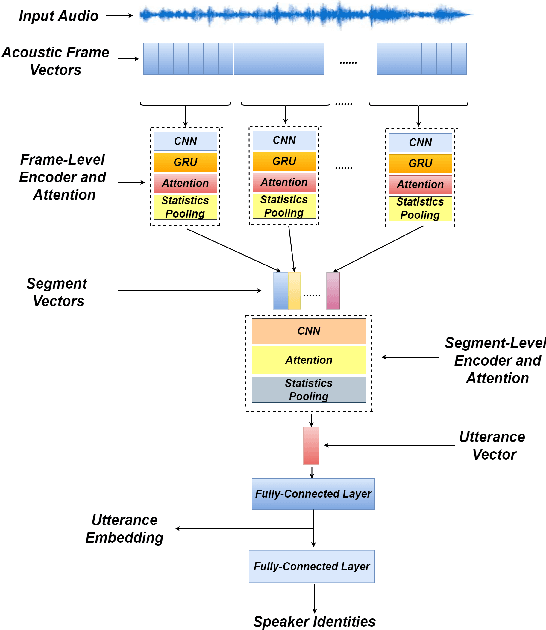

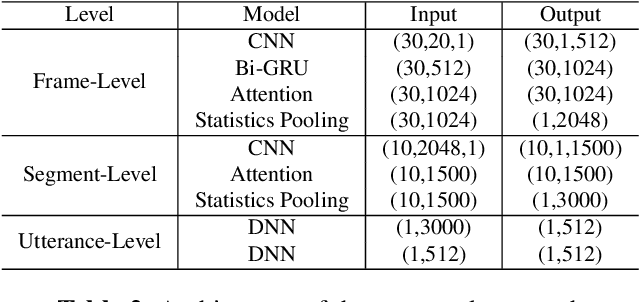

In this paper, a hierarchical attention network to generate utterance-level embeddings (H-vectors) for speaker identification is proposed. Since different parts of an utterance may have different contributions to speaker identities, the use of hierarchical structure aims to learn speaker related information locally and globally. In the proposed approach, frame-level encoder and attention are applied on segments of an input utterance and generate individual segment vectors. Then, segment level attention is applied on the segment vectors to construct an utterance representation. To evaluate the effectiveness of the proposed approach, NIST SRE 2008 Part1 dataset is used for training, and two datasets, Switchboard Cellular part1 and CallHome American English Speech, are used to evaluate the quality of extracted utterance embeddings on speaker identification and verification tasks. In comparison with two baselines, X-vector, X-vector+Attention, the obtained results show that H-vectors can achieve a significantly better performance. Furthermore, the extracted utterance-level embeddings are more discriminative than the two baselines when mapped into a 2D space using t-SNE.