 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Feature Transformation (GFT): A Neural Language Grounding Module for Embodied Agents
Paper and Code


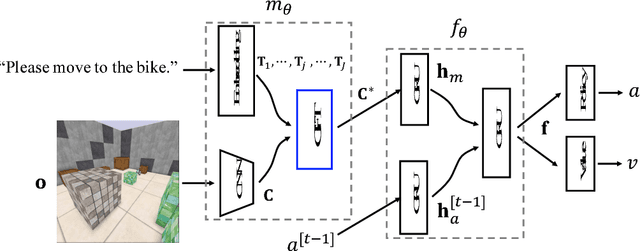
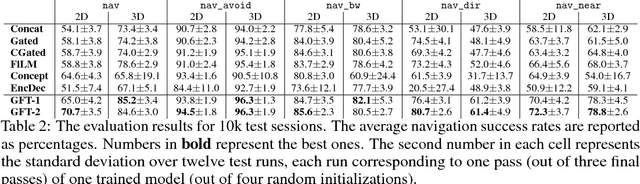
Recently there has been a rising interest in training agents, embodied in virtual environments, to perform language-directed tasks by deep reinforcement learning. In this paper, we propose a simple but effective neural language grounding module for embodied agents that can be trained end to end from scratch taking raw pixels, unstructured linguistic commands, and sparse rewards as the inputs. We model the language grounding process as a language-guided transformation of visual features, where latent sentence embeddings are used as the transformation matrices. In several language-directed navigation tasks that feature challenging partial observability and require simple reasoning, our module significantly outperforms the state of the art. We also release XWorld3D, an easy-to-customize 3D environment that can potentially be modified to evaluate a variety of embodied agents.