Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrowing axons: greedy learning of neural networks with application to function approximation
Paper and Code
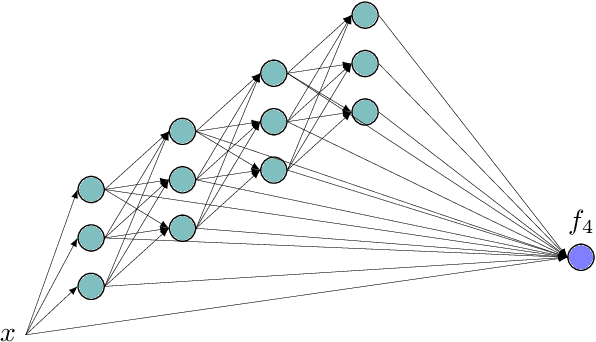
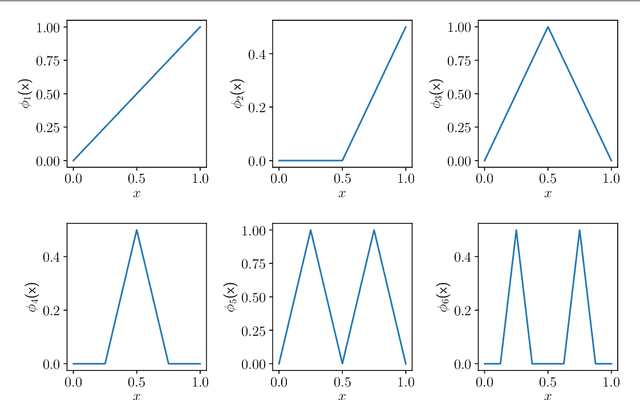
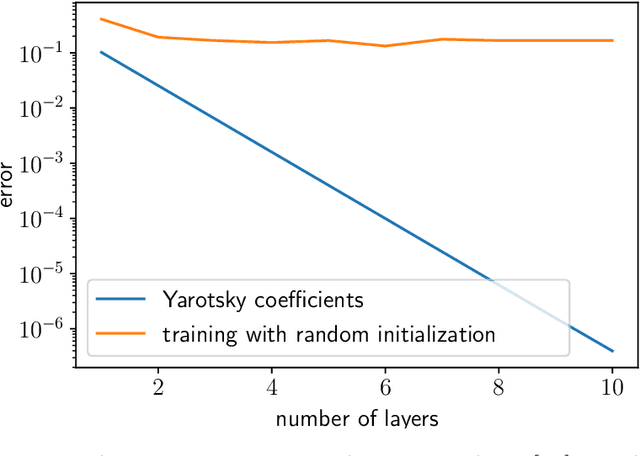
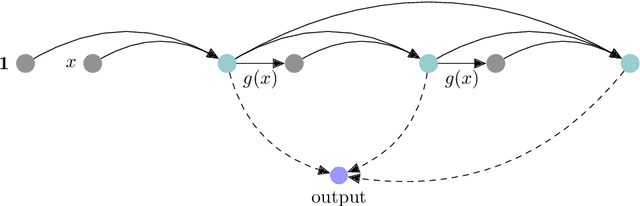
We propose a new method for learning deep neural network models that is based on a greedy learning approach: we add one basis function at a time, and a new basis function is generated as a non-linear activation function applied to a linear combination of the previous basis functions. Such a method (growing deep neural network by one neuron at a time) allows us to compute much more accurate approximants for several model problems in function approximation.
View paper on