 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreMuTRRR: A Novel Genetic Algorithm to Solve Distance Geometry Problem for Protein Structures
Paper and Code
Nov 16, 2014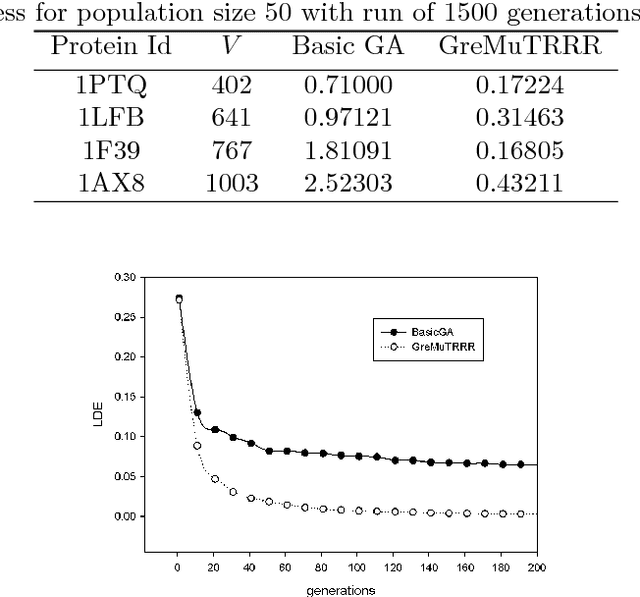
Nuclear Magnetic Resonance (NMR) Spectroscopy is a widely used technique to predict the native structure of proteins. However, NMR machines are only able to report approximate and partial distances between pair of atoms. To build the protein structure one has to solve the Euclidean distance geometry problem given the incomplete interval distance data produced by NMR machines. In this paper, we propose a new genetic algorithm for solving the Euclidean distance geometry problem for protein structure prediction given sparse NMR data. Our genetic algorithm uses a greedy mutation operator to intensify the search, a twin removal technique for diversification in the population and a random restart method to recover stagnation. On a standard set of benchmark dataset, our algorithm significantly outperforms standard genetic algorithms.