 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphical Object-Centric Actor-Critic
Paper and Code
Oct 26, 2023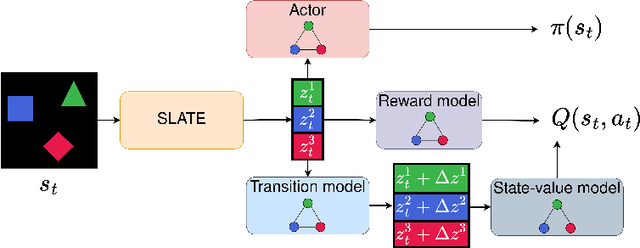
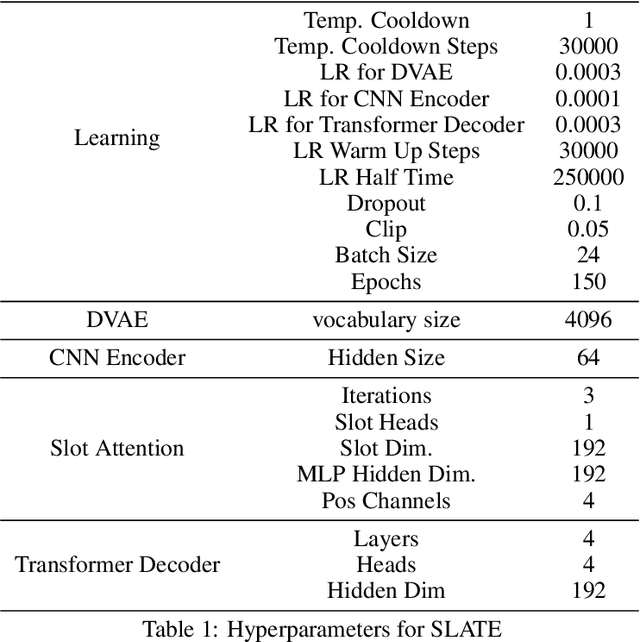
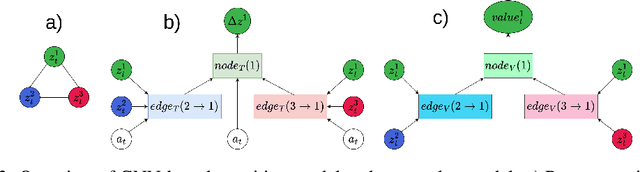

There have recently been significant advances in the problem of unsupervised object-centric representation learning and its application to downstream tasks. The latest works support the argument that employing disentangled object representations in image-based object-centric reinforcement learning tasks facilitates policy learning. We propose a novel object-centric reinforcement learning algorithm combining actor-critic and model-based approaches to utilize these representations effectively. In our approach, we use a transformer encoder to extract object representations and graph neural networks to approximate the dynamics of an environment. The proposed method fills a research gap in developing efficient object-centric world models for reinforcement learning settings that can be used for environments with discrete or continuous action spaces. Our algorithm performs better in a visually complex 3D robotic environment and a 2D environment with compositional structure than the state-of-the-art model-free actor-critic algorithm built upon transformer architecture and the state-of-the-art monolithic model-based algorithm.