Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraduated Optimization of Black-Box Functions
Paper and Code
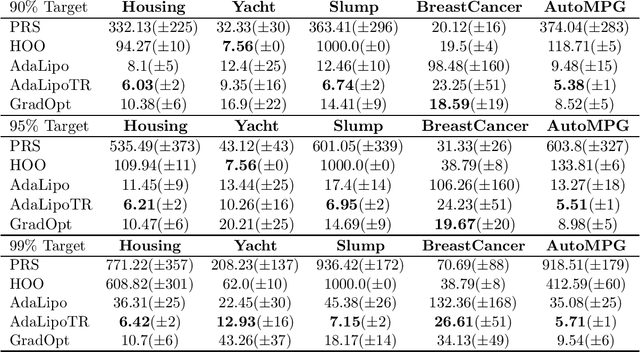
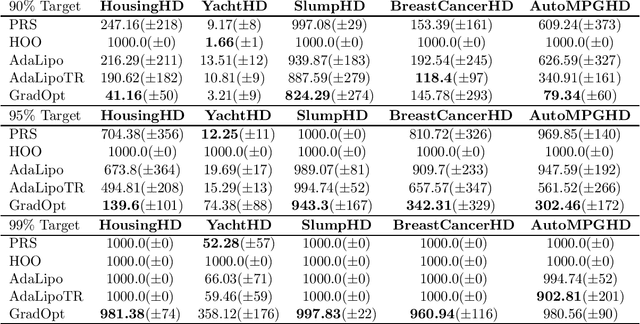
Motivated by the problem of tuning hyperparameters in machine learning, we present a new approach for gradually and adaptively optimizing an unknown function using estimated gradients. We validate the empirical performance of the proposed idea on both low and high dimensional problems. The experimental results demonstrate the advantages of our approach for tuning high dimensional hyperparameters in machine learning.
* Accepted Workshop Submission for the 6th ICML Workshop on Automated
Machine Learning
View paper on