 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Multi-Normalization for Stateless and Scalable LLM Training
Paper and Code
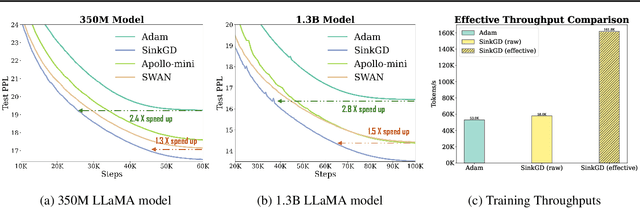
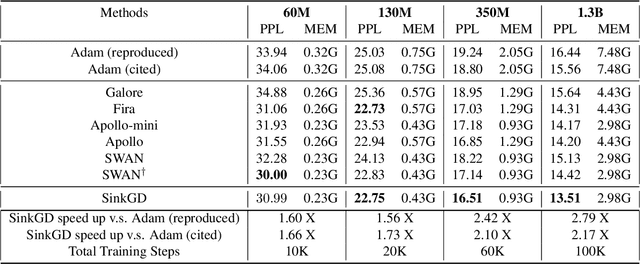
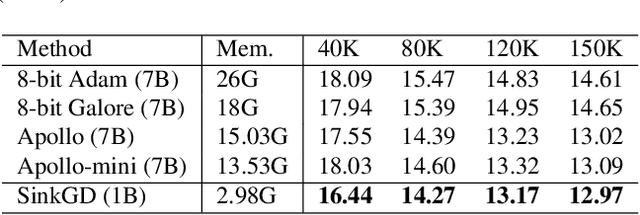

Training large language models (LLMs) typically relies on adaptive optimizers like Adam (Kingma & Ba, 2015) which store additional state information to accelerate convergence but incur significant memory overhead. Recent efforts, such as SWAN (Ma et al., 2024) address this by eliminating the need for optimizer states while achieving performance comparable to Adam via a multi-step preprocessing procedure applied to instantaneous gradients. Motivated by the success of SWAN, we introduce a novel framework for designing stateless optimizers that normalizes stochastic gradients according to multiple norms. To achieve this, we propose a simple alternating scheme to enforce the normalization of gradients w.r.t these norms. We show that our procedure can produce, up to an arbitrary precision, a fixed-point of the problem, and that SWAN is a particular instance of our approach with carefully chosen norms, providing a deeper understanding of its design. However, SWAN's computationally expensive whitening/orthogonalization step limit its practicality for large LMs. Using our principled perspective, we develop of a more efficient, scalable, and practical stateless optimizer. Our algorithm relaxes the properties of SWAN, significantly reducing its computational cost while retaining its memory efficiency, making it applicable to training large-scale models. Experiments on pre-training LLaMA models with up to 1 billion parameters demonstrate a 3X speedup over Adam with significantly reduced memory requirements, outperforming other memory-efficient baselines.