 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Flows in Dataset Space
Paper and Code
Oct 24, 2020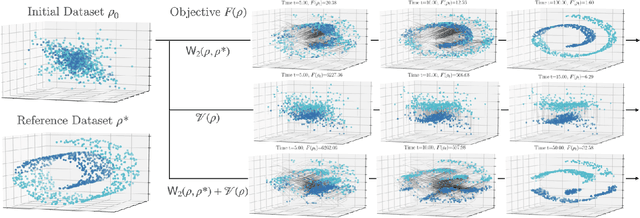
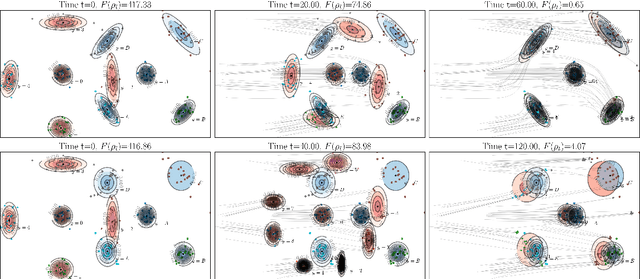
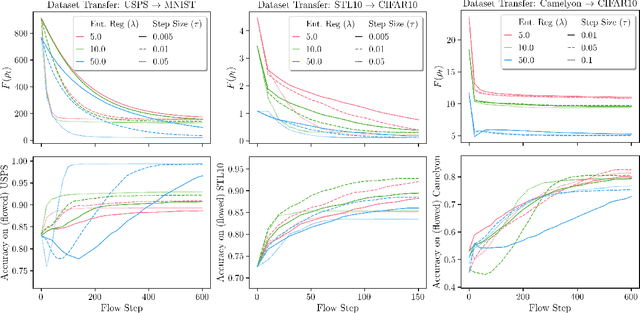
The current practice in machine learning is traditionally model-centric, casting problems as optimization over model parameters, all the while assuming the data is either fixed, or subject to extrinsic and inevitable change. On one hand, this paradigm fails to capture important existing aspects of machine learning, such as the substantial data manipulation (\emph{e.g.}, augmentation) that goes into most state-of-the-art pipelines. On the other hand, this viewpoint is ill-suited to formalize novel data-centric problems, such as model-agnostic transfer learning or dataset synthesis. In this work, we view these and other problems through the lens of \textit{dataset optimization}, casting them as optimization over data-generating distributions. We approach this class of problems through Wasserstein gradient flows in probability space, and derive practical and efficient particle-based methods for a flexible but well-behaved class of objective functions. Through various experiments on synthetic and real datasets, we show that this framework provides a principled and effective approach to dataset shaping, transfer, and interpolation.