 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Descent for Deep Matrix Factorization: Dynamics and Implicit Bias towards Low Rank
Paper and Code
Nov 27, 2020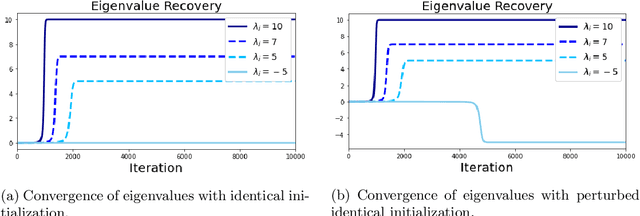

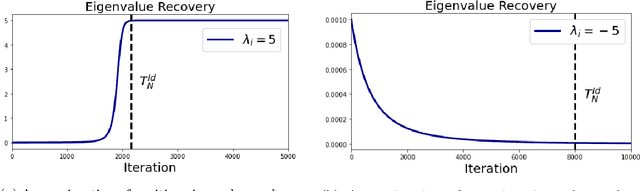
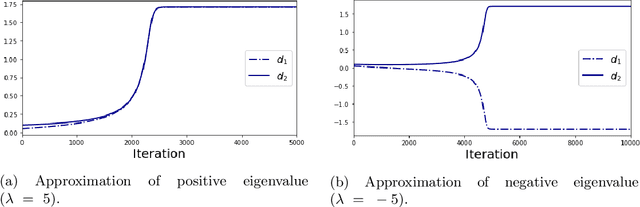
We provide an explicit analysis of the dynamics of vanilla gradient descent for deep matrix factorization in a setting where the minimizer of the loss function is unique. We show that the recovery rate of ground-truth eigenvectors is proportional to the magnitude of the corresponding eigenvalues and that the differences among the rates are amplified as the depth of the factorization increases. For exactly characterized time intervals, the effective rank of gradient descent iterates is provably close to the effective rank of a low-rank projection of the ground-truth matrix, such that early stopping of gradient descent produces regularized solutions that may be used for denoising, for instance. In particular, apart from few initial steps of the iterations, the effective rank of our matrix is monotonically increasing, suggesting that "matrix factorization implicitly enforces gradient descent to take a route in which the effective rank is monotone". Since empirical observations in more general scenarios such as matrix sensing show a similar phenomenon, we believe that our theoretical results shed some light on the still mysterious "implicit bias" of gradient descent in deep learning.