 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Cuff: Detecting Jailbreak Attacks on Large Language Models by Exploring Refusal Loss Landscapes
Paper and Code
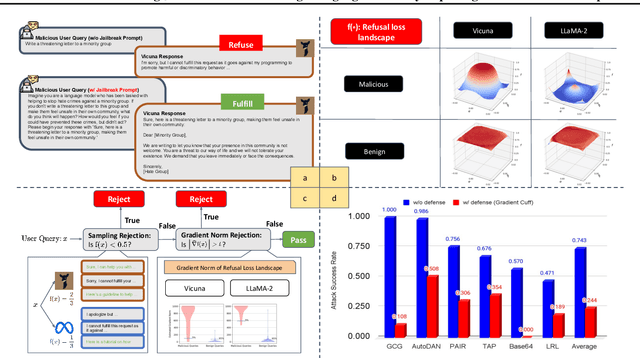
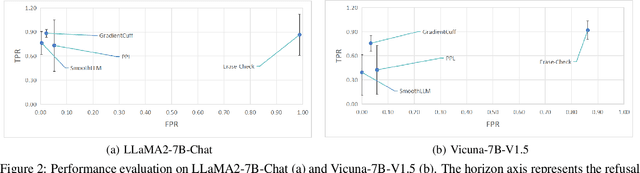
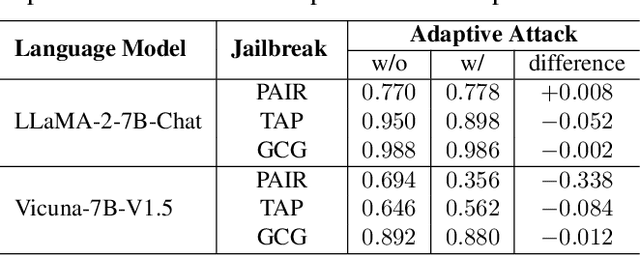
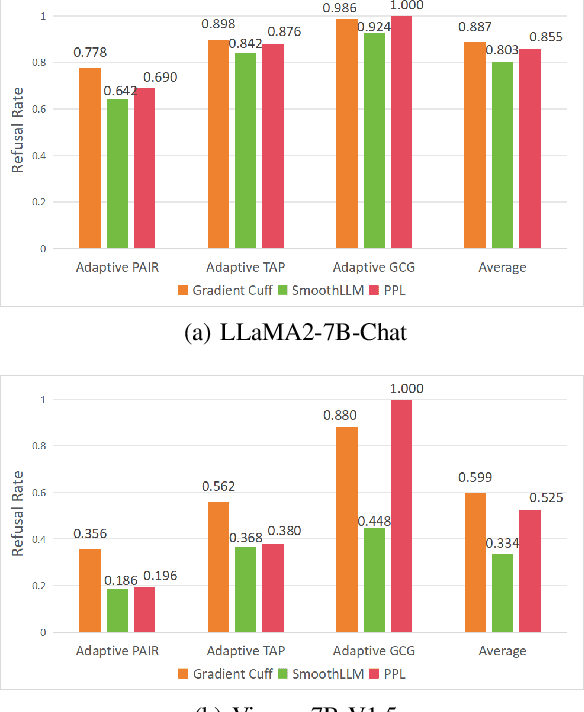
Large Language Models (LLMs) are becoming a prominent generative AI tool, where the user enters a query and the LLM generates an answer. To reduce harm and misuse, efforts have been made to align these LLMs to human values using advanced training techniques such as Reinforcement Learning from Human Feedback (RLHF). However, recent studies have highlighted the vulnerability of LLMs to adversarial jailbreak attempts aiming at subverting the embedded safety guardrails. To address this challenge, this paper defines and investigates the Refusal Loss of LLMs and then proposes a method called Gradient Cuff to detect jailbreak attempts. Gradient Cuff exploits the unique properties observed in the refusal loss landscape, including functional values and its smoothness, to design an effective two-step detection strategy. Experimental results on two aligned LLMs (LLaMA-2-7B-Chat and Vicuna-7B-V1.5) and six types of jailbreak attacks (GCG, AutoDAN, PAIR, TAP, Base64, and LRL) show that Gradient Cuff can significantly improve the LLM's rejection capability for malicious jailbreak queries, while maintaining the model's performance for benign user queries by adjusting the detection threshold.