 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based optimization for variational empirical Bayes multiple regression
Paper and Code


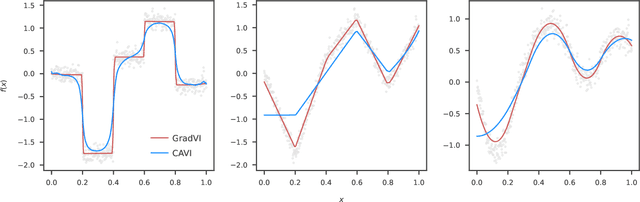

Variational empirical Bayes (VEB) methods provide a practically attractive approach to fitting large, sparse, multiple regression models. These methods usually use coordinate ascent to optimize the variational objective function, an approach known as coordinate ascent variational inference (CAVI). Here we propose alternative optimization approaches based on gradient-based (quasi-Newton) methods, which we call gradient-based variational inference (GradVI). GradVI exploits a recent result from Kim et. al. [arXiv:2208.10910] which writes the VEB regression objective function as a penalized regression. Unfortunately the penalty function is not available in closed form, and we present and compare two approaches to dealing with this problem. In simple situations where CAVI performs well, we show that GradVI produces similar predictive performance, and GradVI converges in fewer iterations when the predictors are highly correlated. Furthermore, unlike CAVI, the key computations in GradVI are simple matrix-vector products, and so GradVI is much faster than CAVI in settings where the design matrix admits fast matrix-vector products (e.g., as we show here, trendfiltering applications) and lends itself to parallelized implementations in ways that CAVI does not. GradVI is also very flexible, and could exploit automatic differentiation to easily implement different prior families. Our methods are implemented in an open-source Python software, GradVI (available from https://github.com/stephenslab/gradvi ).