 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Optimization for Regression in the Functional Tensor-Train Format
Paper and Code
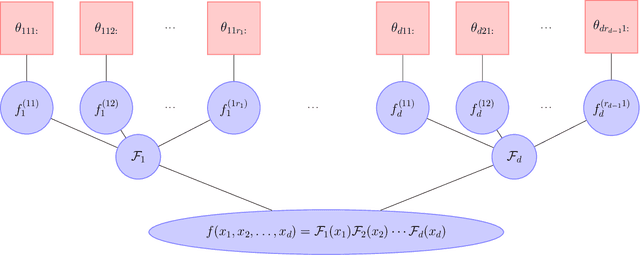


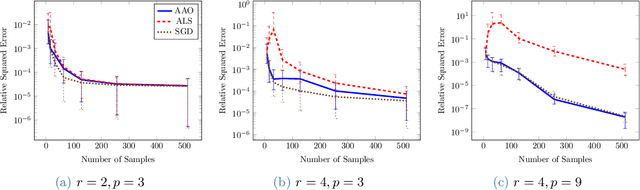
We consider the task of low-multilinear-rank functional regression, i.e., learning a low-rank parametric representation of functions from scattered real-valued data. Our first contribution is the development and analysis of an efficient gradient computation that enables gradient-based optimization procedures, including stochastic gradient descent and quasi-Newton methods, for learning the parameters of a functional tensor-train (FT). The functional tensor-train uses the tensor-train (TT) representation of low-rank arrays as an ansatz for a class of low-multilinear-rank functions. The FT is represented by a set of matrix-valued functions that contain a set of univariate functions, and the regression task is to learn the parameters of these univariate functions. Our second contribution demonstrates that using nonlinearly parameterized univariate functions, e.g., symmetric kernels with moving centers, within each core can outperform the standard approach of using a linear expansion of basis functions. Our final contributions are new rank adaptation and group-sparsity regularization procedures to minimize overfitting. We use several benchmark problems to demonstrate at least an order of magnitude lower accuracy with gradient-based optimization methods than standard alternating least squares procedures in the low-sample number regime. We also demonstrate an order of magnitude reduction in accuracy on a test problem resulting from using nonlinear parameterizations over linear parameterizations. Finally we compare regression performance with 22 other nonparametric and parametric regression methods on 10 real-world data sets. We achieve top-five accuracy for seven of the data sets and best accuracy for two of the data sets. These rankings are the best amongst parametric models and competetive with the best non-parametric methods.