 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT for Semi-Automated Data Science: Introducing CAAFE for Context-Aware Automated Feature Engineering
Paper and Code
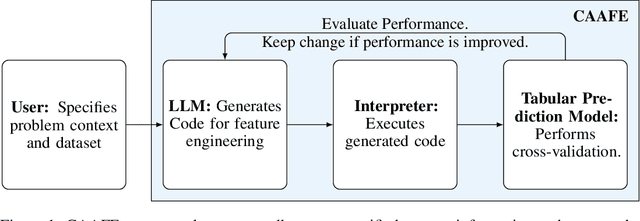
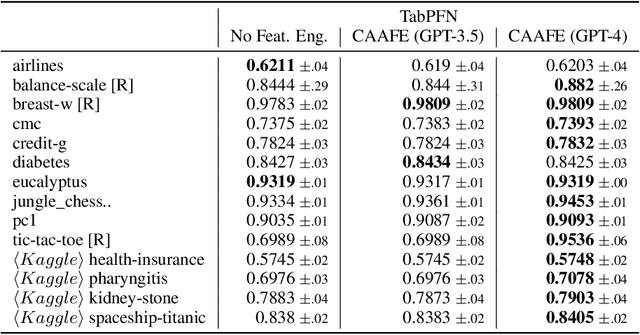
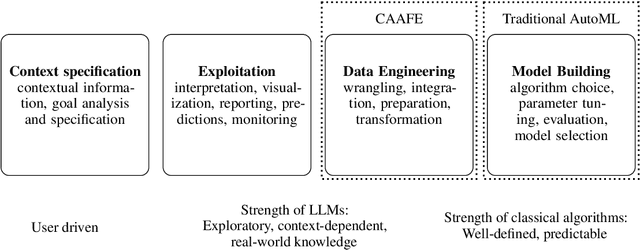
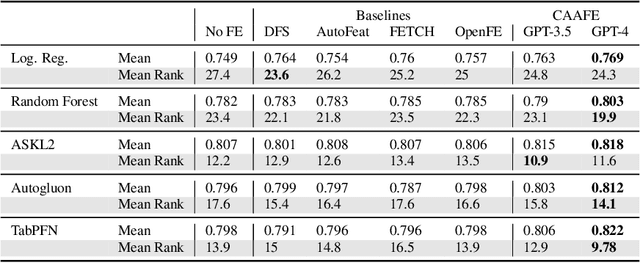
As the field of automated machine learning (AutoML) advances, it becomes increasingly important to include domain knowledge within these systems. We present an approach for doing so by harnessing the power of large language models (LLMs). Specifically, we introduce Context-Aware Automated Feature Engineering (CAAFE), a feature engineering method for tabular datasets that utilizes an LLM to generate additional semantically meaningful features for tabular datasets based on their descriptions. The method produces both Python code for creating new features and explanations for the utility of the generated features. Despite being methodologically simple, CAAFE enhances performance on 11 out of 14 datasets, ties on 2 and looses on 1 - boosting mean ROC AUC performance from 0.798 to 0.822 across all datasets. On the evaluated datasets, this improvement is similar to the average improvement achieved by using a random forest (AUC 0.782) instead of logistic regression (AUC 0.754). Furthermore, our method offers valuable insights into the rationale behind the generated features by providing a textual explanation for each generated feature. CAAFE paves the way for more extensive (semi-)automation in data science tasks and emphasizes the significance of context-aware solutions that can extend the scope of AutoML systems. For reproducability, we release our code and a simple demo.