 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Arm Identification via Bandit Feedback
Paper and Code
Feb 10, 2018
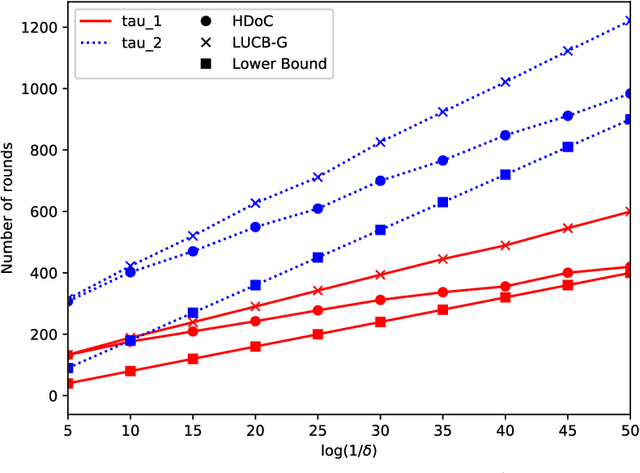
We consider a novel stochastic multi-armed bandit problem called {\em good arm identification} (GAI), where a good arm is defined as an arm with expected reward greater than or equal to a given threshold. GAI is a pure-exploration problem that a single agent repeats a process of outputting an arm as soon as it is identified as a good one before confirming the other arms are actually not good. The objective of GAI is to minimize the number of samples for each process. We find that GAI faces a new kind of dilemma, the {\em exploration-exploitation dilemma of confidence}, which is different difficulty from the best arm identification. As a result, an efficient design of algorithms for GAI is quite different from that for the best arm identification. We derive a lower bound on the sample complexity of GAI that is tight up to the logarithmic factor $\mathrm{O}(\log \frac{1}{\delta})$ for acceptance error rate $\delta$. We also develop an algorithm whose sample complexity almost matches the lower bound. We also confirm experimentally that our proposed algorithm outperforms naive algorithms in synthetic settings based on a conventional bandit problem and clinical trial researches for rheumatoid arthritis.