 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Minima of DNNs: The Plenty Pantry
Paper and Code
May 25, 2019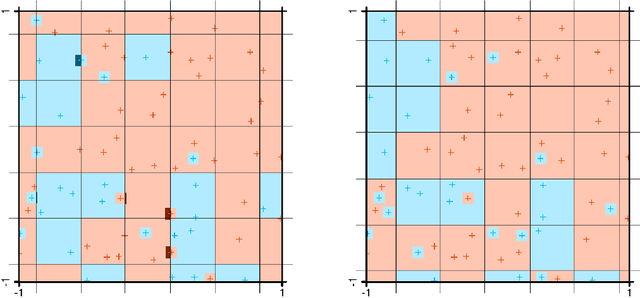
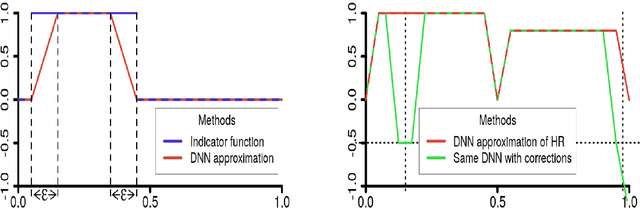
A common strategy to train deep neural networks (DNNs) is to use very large architectures and to train them until they (almost) achieve zero training error. Empirically observed good generalization performance on test data, even in the presence of lots of label noise, corroborate such a procedure. On the other hand, in statistical learning theory it is known that over-fitting models may lead to poor generalization properties, occurring in e.g. empirical risk minimization (ERM) over too large hypotheses classes. Inspired by this contradictory behavior, so-called interpolation methods have recently received much attention, leading to consistent and optimally learning methods for some local averaging schemes with zero training error. However, there is no theoretical analysis of interpolating ERM-like methods so far. We take a step in this direction by showing that for certain, large hypotheses classes, some interpolating ERMs enjoy very good statistical guarantees while others fail in the worst sense. Moreover, we show that the same phenomenon occurs for DNNs with zero training error and sufficiently large architectures.