 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Data Constraints: Ethical and Effectiveness Challenges in Large Language Model
Paper and Code
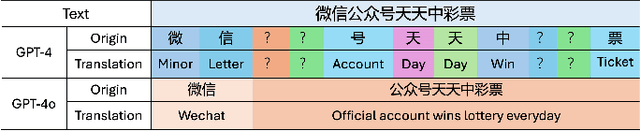



The efficacy and ethical integrity of large language models (LLMs) are profoundly influenced by the diversity and quality of their training datasets. However, the global landscape of data accessibility presents significant challenges, particularly in regions with stringent data privacy laws or limited open-source information. This paper examines the multifaceted challenges associated with acquiring high-quality training data for LLMs, focusing on data scarcity, bias, and low-quality content across various linguistic contexts. We highlight the technical and ethical implications of relying on publicly available but potentially biased or irrelevant data sources, which can lead to the generation of biased or hallucinatory content by LLMs. Through a series of evaluations using GPT-4 and GPT-4o, we demonstrate how these data constraints adversely affect model performance and ethical alignment. We propose and validate several mitigation strategies designed to enhance data quality and model robustness, including advanced data filtering techniques and ethical data collection practices. Our findings underscore the need for a proactive approach in developing LLMs that considers both the effectiveness and ethical implications of data constraints, aiming to foster the creation of more reliable and universally applicable AI systems.