 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Bandits with Holder Continuity
Paper and Code
Oct 29, 2014
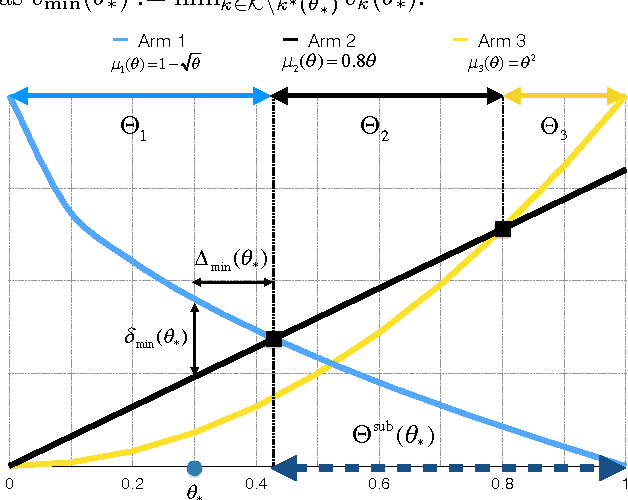
Standard Multi-Armed Bandit (MAB) problems assume that the arms are independent. However, in many application scenarios, the information obtained by playing an arm provides information about the remainder of the arms. Hence, in such applications, this informativeness can and should be exploited to enable faster convergence to the optimal solution. In this paper, we introduce and formalize the Global MAB (GMAB), in which arms are globally informative through a global parameter, i.e., choosing an arm reveals information about all the arms. We propose a greedy policy for the GMAB which always selects the arm with the highest estimated expected reward, and prove that it achieves bounded parameter-dependent regret. Hence, this policy selects suboptimal arms only finitely many times, and after a finite number of initial time steps, the optimal arm is selected in all of the remaining time steps with probability one. In addition, we also study how the informativeness of the arms about each other's rewards affects the speed of learning. Specifically, we prove that the parameter-free (worst-case) regret is sublinear in time, and decreases with the informativeness of the arms. We also prove a sublinear in time Bayesian risk bound for the GMAB which reduces to the well-known Bayesian risk bound for linearly parameterized bandits when the arms are fully informative. GMABs have applications ranging from drug and treatment discovery to dynamic pricing.