 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGitHub Typo Corpus: A Large-Scale Multilingual Dataset of Misspellings and Grammatical Errors
Paper and Code


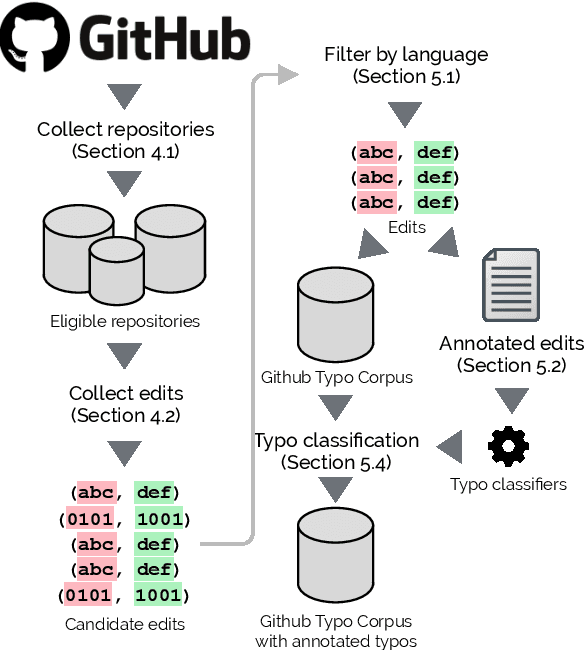
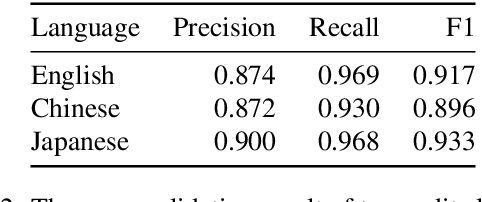
The lack of large-scale datasets has been a major hindrance to the development of NLP tasks such as spelling correction and grammatical error correction (GEC). As a complementary new resource for these tasks, we present the GitHub Typo Corpus, a large-scale, multilingual dataset of misspellings and grammatical errors along with their corrections harvested from GitHub, a large and popular platform for hosting and sharing git repositories. The dataset, which we have made publicly available, contains more than 350k edits and 65M characters in more than 15 languages, making it the largest dataset of misspellings to date. We also describe our process for filtering true typo edits based on learned classifiers on a small annotated subset, and demonstrate that typo edits can be identified with F1 ~ 0.9 using a very simple classifier with only three features. The detailed analyses of the dataset show that existing spelling correctors merely achieve an F-measure of approx. 0.5, suggesting that the dataset serves as a new, rich source of spelling errors that complement existing datasets.