 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGERE: Generative Evidence Retrieval for Fact Verification
Paper and Code
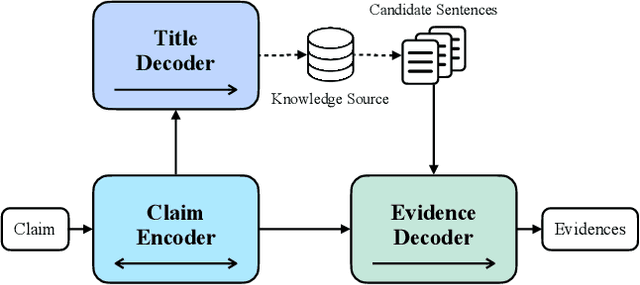
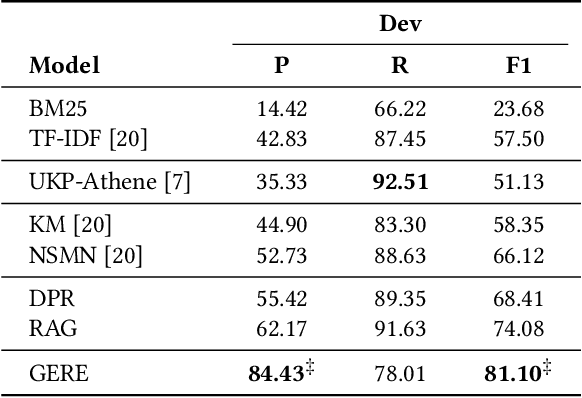
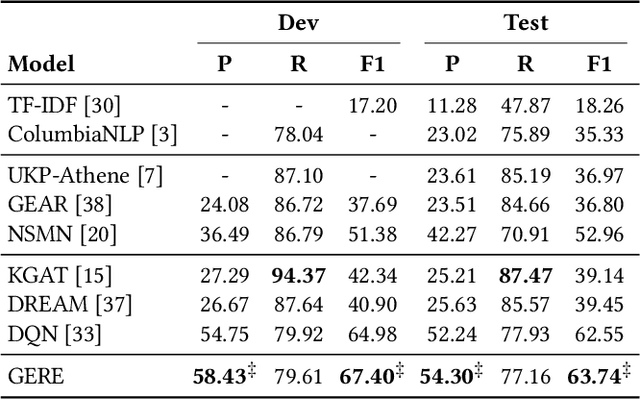
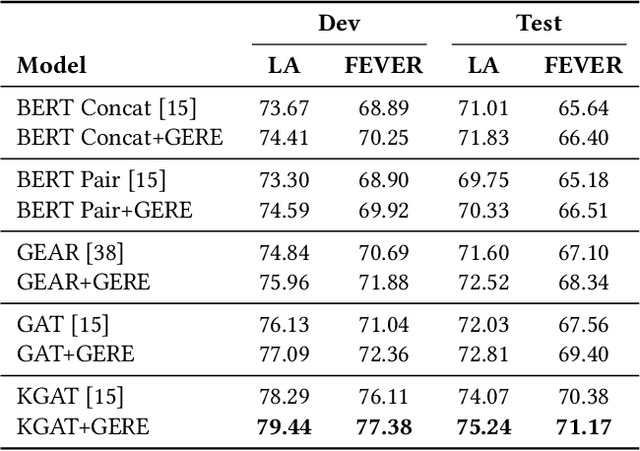
Fact verification (FV) is a challenging task which aims to verify a claim using multiple evidential sentences from trustworthy corpora, e.g., Wikipedia. Most existing approaches follow a three-step pipeline framework, including document retrieval, sentence retrieval and claim verification. High-quality evidences provided by the first two steps are the foundation of the effective reasoning in the last step. Despite being important, high-quality evidences are rarely studied by existing works for FV, which often adopt the off-the-shelf models to retrieve relevant documents and sentences in an "index-retrieve-then-rank" fashion. This classical approach has clear drawbacks as follows: i) a large document index as well as a complicated search process is required, leading to considerable memory and computational overhead; ii) independent scoring paradigms fail to capture the interactions among documents and sentences in ranking; iii) a fixed number of sentences are selected to form the final evidence set. In this work, we propose GERE, the first system that retrieves evidences in a generative fashion, i.e., generating the document titles as well as evidence sentence identifiers. This enables us to mitigate the aforementioned technical issues since: i) the memory and computational cost is greatly reduced because the document index is eliminated and the heavy ranking process is replaced by a light generative process; ii) the dependency between documents and that between sentences could be captured via sequential generation process; iii) the generative formulation allows us to dynamically select a precise set of relevant evidences for each claim. The experimental results on the FEVER dataset show that GERE achieves significant improvements over the state-of-the-art baselines, with both time-efficiency and memory-efficiency.