 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoMLAMA: Geo-Diverse Commonsense Probing on Multilingual Pre-Trained Language Models
Paper and Code

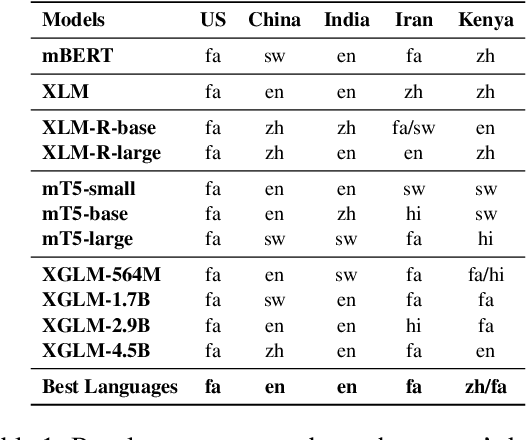
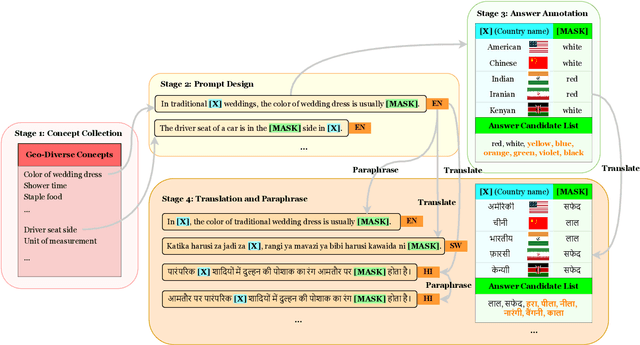

Recent work has shown that Pre-trained Language Models (PLMs) have the ability to store the relational knowledge from pre-training data in their model parameters. However, it is not clear up to what extent do PLMs store geo-diverse commonsense knowledge, the knowledge associated with a culture and only shared locally. For instance, the color of bridal dress is white in American weddings whereas it is red in Chinese weddings. Here, we wish to probe if PLMs can predict red and white as the color of the bridal dress when queried for American and Chinese weddings, respectively. To this end, we introduce a framework for geo-diverse commonsense probing on multilingual PLMs (mPLMs) and introduce a corresponding benchmark Geo-diverse Commonsense Multilingual Language Model Analysis (GeoMLAMA) dataset. GeoMLAMA contains 3125 prompts in English, Chinese, Hindi, Persian, and Swahili, with a wide coverage of concepts shared by people from American, Chinese, Indian, Iranian and Kenyan cultures. We benchmark 11 standard mPLMs which include variants of mBERT, XLM, mT5, and XGLM on GeoMLAMA. Interestingly, we find that 1) larger mPLM variants do not necessarily store geo-diverse concepts better than its smaller variant; 2) mPLMs are not intrinsically biased towards knowledge from the Western countries (the United States); 3) the native language of a country may not be the best language to probe its knowledge and 4) a language may better probe knowledge about a non-native country than its native country.