Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry of Policy Improvement
Paper and Code
Apr 06, 2017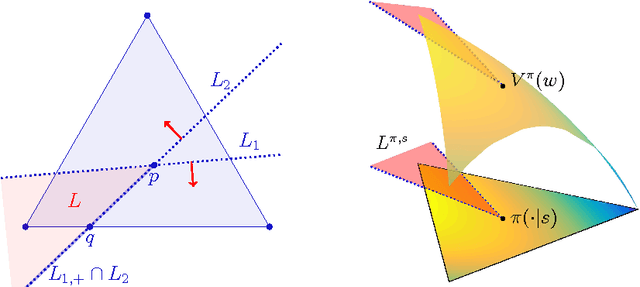
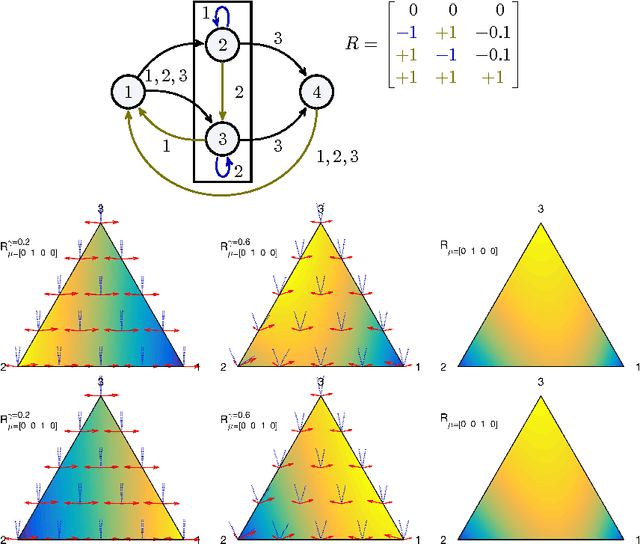
We investigate the geometry of optimal memoryless time independent decision making in relation to the amount of information that the acting agent has about the state of the system. We show that the expected long term reward, discounted or per time step, is maximized by policies that randomize among at most $k$ actions whenever at most $k$ world states are consistent with the agent's observation. Moreover, we show that the expected reward per time step can be studied in terms of the expected discounted reward. Our main tool is a geometric version of the policy improvement lemma, which identifies a polyhedral cone of policy changes in which the state value function increases for all states.
* 8 pages
View paper on