 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENEVA: Pushing the Limit of Generalizability for Event Argument Extraction with 100+ Event Types
Paper and Code
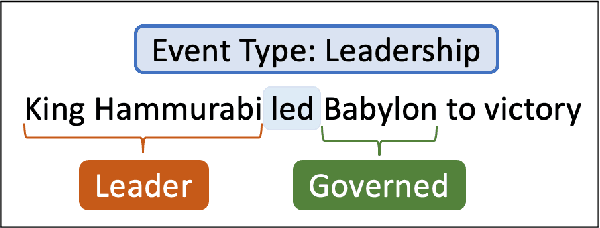
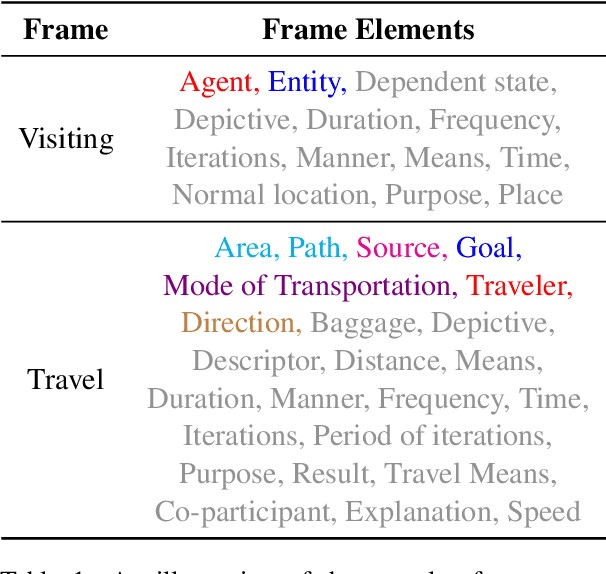

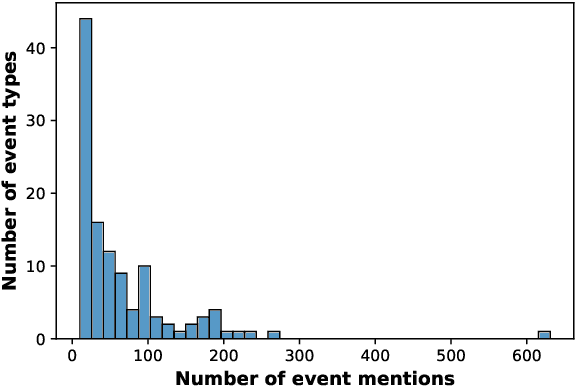
Numerous events occur worldwide and are documented in the news, social media, and various online platforms in raw text. Extracting useful and succinct information about these events is crucial to various downstream applications. Event Argument Extraction (EAE) deals with the task of extracting event-specific information from natural language text. In order to cater to new events and domains in a realistic low-data setting, there is a growing urgency for EAE models to be generalizable. Consequentially, there is a necessity for benchmarking setups to evaluate the generalizability of EAE models. But most existing benchmarking datasets like ACE and ERE have limited coverage in terms of events and cannot adequately evaluate the generalizability of EAE models. To alleviate this issue, we introduce a new dataset GENEVA covering a diverse range of 115 events and 187 argument roles. Using this dataset, we create four benchmarking test suites to assess the model's generalization capability from different perspectives. We benchmark various representative models on these test suites and compare their generalizability relatively. Finally, we propose a new model SCAD that outperforms the previous models and serves as a strong benchmark for these test suites.