 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneric Machine Learning Inference on Heterogenous Treatment Effects in Randomized Experiments
Paper and Code
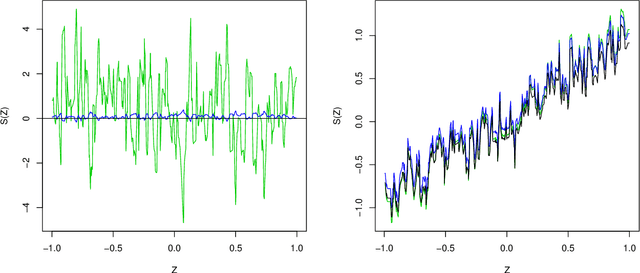
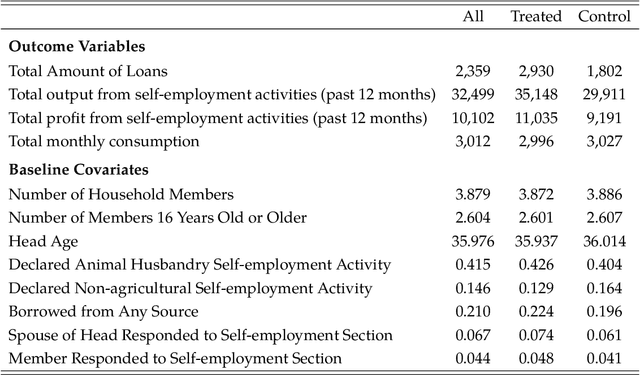
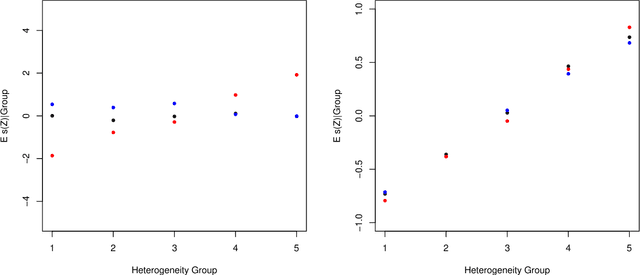
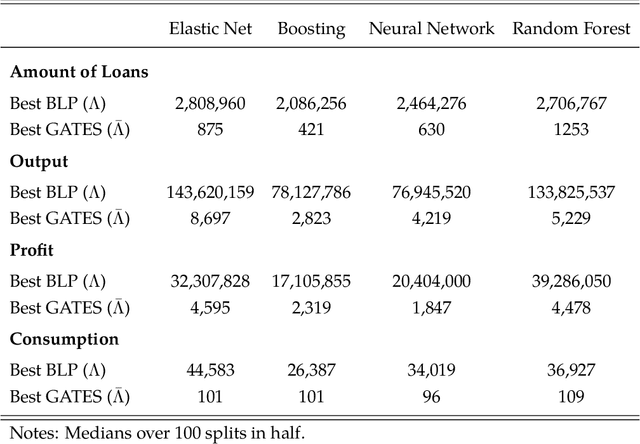
We propose strategies to estimate and make inference on key features of heterogeneous effects in randomized experiments. These key features include best linear predictors of the effects using machine learning proxies, average effects sorted by impact groups, and average characteristics of most and least impacted units. The approach is valid in high dimensional settings, where the effects are proxied by machine learning methods. We post-process these proxies into the estimates of the key features. Our approach is generic, it can be used in conjunction with penalized methods, deep and shallow neural networks, canonical and new random forests, boosted trees, and ensemble methods. Our approach is agnostic and does not make unrealistic or hard-to-check assumptions; we don't require conditions for consistency of the ML methods. Estimation and inference relies on repeated data splitting to avoid overfitting and achieve validity. For inference, we take medians of p-values and medians of confidence intervals, resulting from many different data splits, and then adjust their nominal level to guarantee uniform validity. This variational inference method is shown to be uniformly valid and quantifies the uncertainty coming from both parameter estimation and data splitting. The inference method could be of substantial independent interest in many machine learning applications. An empirical application to the impact of micro-credit on economic development illustrates the use of the approach in randomized experiments. An additional application to the impact of the gender discrimination on wages illustrates the potential use of the approach in observational studies, where machine learning methods can be used to condition flexibly on very high-dimensional controls.