 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Video Bi-flow
Paper and Code
Mar 09, 2025

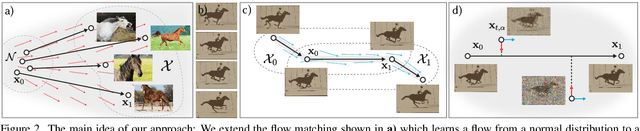

We propose a novel generative video model by robustly learning temporal change as a neural Ordinary Differential Equation (ODE) flow with a bilinear objective of combining two aspects: The first is to map from the past into future video frames directly. Previous work has mapped the noise to new frames, a more computationally expensive process. Unfortunately, starting from the previous frame, instead of noise, is more prone to drifting errors. Hence, second, we additionally learn how to remove the accumulated errors as the joint objective by adding noise during training. We demonstrate unconditional video generation in a streaming manner for various video datasets, all at competitive quality compared to a baseline conditional diffusion but with higher speed, i.e., fewer ODE solver steps.