Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modeling for Low Dimensional Speech Attributes with Neural Spline Flows
Paper and Code

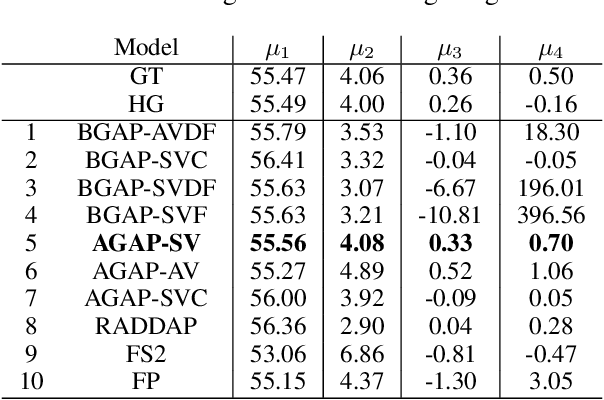

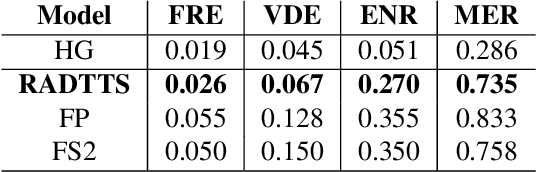
Despite recent advances in generative modeling for text-to-speech synthesis, these models do not yet have the same fine-grained adjustability of pitch-conditioned deterministic models such as FastPitch and FastSpeech2. Pitch information is not only low-dimensional, but also discontinuous, making it particularly difficult to model in a generative setting. Our work explores several techniques for handling the aforementioned issues in the context of Normalizing Flow models. We also find this problem to be very well suited for Neural Spline flows, which is a highly expressive alternative to the more common affine-coupling mechanism in Normalizing Flows.
* 22 pages, 11 figures, 3 tables
View paper on