 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative error correction for code-switching speech recognition using large language models
Paper and Code


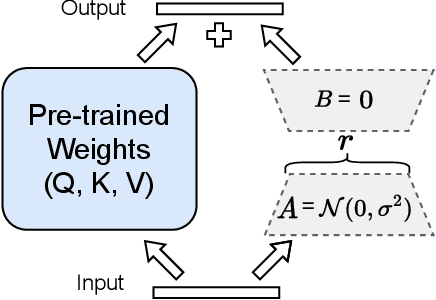

Code-switching (CS) speech refers to the phenomenon of mixing two or more languages within the same sentence. Despite the recent advances in automatic speech recognition (ASR), CS-ASR is still a challenging task ought to the grammatical structure complexity of the phenomenon and the data scarcity of specific training corpus. In this work, we propose to leverage large language models (LLMs) and lists of hypotheses generated by an ASR to address the CS problem. Specifically, we first employ multiple well-trained ASR models for N-best hypotheses generation, with the aim of increasing the diverse and informative elements in the set of hypotheses. Next, we utilize the LLMs to learn the hypotheses-to-transcription (H2T) mapping by adding a trainable low-rank adapter. Such a generative error correction (GER) method directly predicts the accurate transcription according to its expert linguistic knowledge and N-best hypotheses, resulting in a paradigm shift from the traditional language model rescoring or error correction techniques. Experimental evidence demonstrates that GER significantly enhances CS-ASR accuracy, in terms of reduced mixed error rate (MER). Furthermore, LLMs show remarkable data efficiency for H2T learning, providing a potential solution to the data scarcity problem of CS-ASR in low-resource languages.